
확률 변수의 평균과 분산
- 양적 자료에 대한 평균은 도수 히스토그램의 중심 위치를 나타내고, 분산은 평균을 중심으로 흩어진 정도를 나타낸다.
- 이와 마찬가지로 확률 변수 `X` 의 분포에 대한 중심 위치인 평균과 이 값을 중심으로 흩어진 정도인 분산을 정의할 수 있다.
확률 변수의 평균
- 어느 마트에서 창립 기념으로 고객에게 상품권을 제공하는 시은행사를 실시한다.
- 이 마트에서 제작한 복권의 수와 상품권 금액은 다음과 같다.
| 상품권 | 복권 수 |
| 100만원 | 2 |
| 50만원 | 8 |
| 10만원 | 10 |
| 0원 | 30 |
- 이 마트에서 고객에게 제공하는 상금의 평균을 $\overline{x}$ 라 하면 다음과 같이 구할 수 있다.
| $$\overline{x} = \frac{1}{50}(0 \times 30 + 10 \times 10 + 50 \times 8 + 100 \times 2) = 0 \times \frac{30}{50} + 10 \times \frac{10}{50} + 50 \times \frac{8}{50} + 100 \times \frac{2}{5} = 14$$ |
- 이 때, 상품권의 금액을 확률 변수 `X` 라 하면 이 확률 변수는 이산 확률 변수이다.
- 그리고 `X` 가 취할 수 있는 값은 0원, 10만원, 50만원, 100만원이고, 각 상금에 대한 확률을 나타내면 다음과 같다.
| `X` | 0 | 10 | 50 | 100 |
| `f(x)` | $\frac{3}{5}$ | $\frac{1}{5}$ | $\frac{4}{25}$ | $\frac{1}{25}$ |
- 그러면 이산 확률 변수 `X` 의 평균은 확률 변수가 취하는 값과 그에 대응하는 확률의 곱을 모두 더한 것과 동일한 것을 알 수 있다.
- 그리고 확률 변수 `X` 의 평균은 다음과 같이 확률 히스토그램의 중심 위치를 나타낸다.

- 이와 같이 이산 확률 변수 `X` 의 확률 분포가 아래와 같을 때, `X` 의 평균은 다음과 같다.
$$\overline{x} = x_{1}p_{1} + x_{2}p_{2} + x_{3}p_{3} + \cdots + x_{n}p_{n} = \sum_{i = 1}^{n}x_{i}p_{i}$$
| $X$ | $x_{1}$ | $x_{2}$ | $x_{3}$ | $\cdots$ | $x_{n}$ | 합계 |
| $f(x)$ | $p_{1}$ | $p_{2}$ | $p_{3}$ | $\cdots$ | $p_{n}$ | $1$ |
- 즉, 이산 확률 변수 `X` 의 평균은 이 확률 변수가 취할 수 있는 모든 값과 그에 대응하는 확률의 곱을 더하여 얻는다.
- 이와 마찬가지로 연속 확률 변수 `X` 의 평균은 확률 변수가 취할 수 있는 모든 값과 그에 대응하는 확률 밀도 함수의 곱을 적분하여 얻는다.
- 이 때, 확률 변수의 평균을 기댓값이라 한다.
기댓값(Expected Value)
확률 변수 `X` 에 대해 다음과 같이 정의되는 수치 $μ = E(X)$ 를 `X` 의 기댓값(Expected Value) 또는 평균(Mean)이라 한다.
$$μ = E(X) = \begin{cases} \sum\limits_{모든(x \in S_{X})} xf(x), & \text{X가 이산 확률 변수인 경우} \\ \int_{-\infty}^{\infty} xf(x)dx, & \text{X가 연속 확률 변수인 경우} \end{cases}$$
예제 : 주사위를 두 번 반복하여 던지는 시행에서 두 눈의 차의 절댓값을 확률 변수 `X` 라 할 때, `X` 의 기댓값 `E(X)` 를 구하라.
확률 변수 `X` 의 확률 분포를 나타내면 다음과 같다.
| `X` | 0 | 1 | 2 | 3 | 4 | 5 | 합계 |
| `P(X = x)` | $\frac{6}{36}$ | $\frac{10}{36}$ | $\frac{8}{36}$ | $\frac{6}{36}$ | $\frac{4}{36}$ | $\frac{2}{36}$ | 1 |
따라서 `X` 의 기댓값을 구하면 다음과 같다.
$\displaystyle E(X) = 0 \times \frac{6}{36} + 1 \times \frac{10}{36} + 2 \times \frac{8}{36} + 3 \times \frac{6}{36} + 4 \times \frac{4}{36} + 5 \times \frac{2}{36} = \frac{35}{18} ≒ 1.944$
기댓값의 성질
- 이산 확률 변수 `X` 의 확률 질량 함수를 `f(x)` 라 하면, $Y = aX + b, \; a \ne 0$ 의 기댓값은 다음과 같다.
$$E(aX + b) = \sum_{x \in S_{x}}(ax + b)f(x) = \sum_{x \in S_{X}}[axf(x) + bf(x)] = a\sum_{x \in S_{X}}xf(x) + b\sum_{x \in S_{X}}f(x) = aE(X) + b$$
- 따라서 확률 변수 `X` 에 대해 다음과 같은 기댓값의 성질을 얻는다. (단, `a, b` 는 상수이다.)
① $E(a) = a$
② $E(aX) = aE(X)$
③ $E(aX + b) = aE(X) + b$
확률 변수 `X` 의 함수인 `Y = g(x)` 의 기댓값
- 확률 변수 `X` 의 함수인 `Y = g(x)` 의 기댓값은 다음과 같다.
$$E(g(X)) = \begin{cases} \sum\limits_{모든(x \in S_{X})} g(x)f(x), & \text{X가 이산 확률 변수인 경우} \\ \int_{-\infty}^{\infty} g(x)f(x)dx, & \text{X가 연속 확률 변수인 경우} \end{cases}$$
예제 : 연속 확률 변수 `X` 의 확률 밀도 함수가 $\displaystyle f(x) = \frac{3}{8}x^{2}, \; 0 \le x \le 2$ 일 때, 다음을 구하라.
(a) `X` 의 기댓값
(b) `2X + 1` 의 기댓값
(c) $X^{2}$ 의 기댓값
(a)
$\displaystyle E(X) = \int_{-\infty}^{\infty} xf(x)dx = \frac{3}{8} \int_{0}^{2}x^{3}dx = \left [ \frac{3}{32}x^{4} \right ]^{2}_{0} = \frac{3}{2}$
(b)
$\displaystyle E(2X + 1) = 2E(X) + 1 = 2 \times \frac{3}{2} + 1 = 4$
(c)
$\displaystyle E(X^{2}) = \int_{-\infty}^{\infty} x^{2}f(x)dx = \frac{3}{8} \int_{0}^{2} x^{4}dx = \left [\frac{3}{40} x^{5} \right ]^{2}_{0} = \frac{12}{5}$
확률 변수의 분산
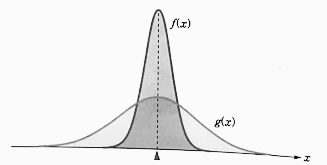
- 아래 그림의 두 확률 분포는 중심 위치인 평균은 동일하지만, 평균을 중심으로 밀집하는 정도가 다르다.
- 따라서 확률 분포의 특징을 결정짓는 중요한 척도로, 밀집 정도를 나타내는 산포의 척도인 분산을 생각할 수 있다.
확률 변수의 분산(Variance)과 표준 편차(Standard Deviation)
① 분산(Variance) : 확률 변수 `X` 의 평균 $μ = E(X)$ 에 대해 평균 편차의 제곱 $(X - μ)^{2}$ 에 대한 평균 $E[(X-μ)^{2}], \; σ^{2}$ 또는 $\text{Var}(X)$ 로 나타낸다.
② 표준 편차(Standard Deviation) : 분산의 양의 제곱근 $\sqrt{\text{Var}(X)}$
- 예를 들어, 다음과 같이 주어진 이산 확률 변수 `X` 의 평균을 $μ = E(X)$ 라 하자.
| $X$ | $x_{1}$ | $x_{2}$ | $x_{3}$ | $\cdots$ | $x_{n}$ |
| $(X - μ)^{2}$ | $(x_{1} - μ)^{2}$ | $(x_{2} - μ)^{2}$ | $(x_{3} - μ)^{2}$ | $\cdots$ | $(x_{n} - μ)^{2}$ |
| $f(x)$ | $p_{1}$ | $p_{2}$ | $p_{3}$ | $\cdots$ | $p_{n}$ |
- 그러면 `X` 의 분산은 확률 변수 `X` 와 평균 `μ` 의 편차 제곱 $(X - μ)^{2}$ 의 평균이므로 다음을 얻는다.
$$\text{Var}(X) = E[(X-μ)^{2}] = \sum_{i=1}^{n}(x_{i} - μ)^{2}p_{i} = \sum_{i=1}^{n}(x_{i}^{2}p_{i} - 2μx_{i}p_{i} + μ^{2}p_{i}) = \sum_{i=1}^{n}x_{i}^{2}p_{i} - 2μ\sum_{i=1}^{n}x_{i}p_{i} + μ^{2}\sum_{i=1}^{n}p_{i}$$
- 이 떄, `μ` 는 이산 확률 변수 `X` 의 평균이고, $p_{i}, \; i = 1, 2, \cdots, n$ 는 `X` 가 취할 수 있는 각 경우의 확률이므로 다음을 얻는다.
$$E(X^{2}) = \sum_{i=1}^{n}x_{i}^{2}p_{i}, \quad μ = \sum_{i=1}^{n}x_{i}p_{i}, \quad \sum_{i=1}^{n}p_{i} = 1$$
- 따라서 이산 확률 변수 `X` 의 분산은 $\text{Var}(X) = E(X^{2}) - μ^{2}$ 이다.
- 이는 연속 확률 변수에 대해서도 동일하게 적용된다.
- 그러므로 다음과 같이 분산을 쉽게 구할 수 있다.
$$\text{Var}(X) = E(X^{2}) - μ^{2} = E(X^{2}) - (E(X))^{2}$$
분산의 성질
- 기댓값의 성질과 분산의 정의로부터 다음의 성질을 쉽게 얻을 수 있다.
① $\text{Var}(a) = 0$
② $\text{Var}(aX) = a^{2}\text{Var}(X)$
③ $\text{Var}(aX + b) = a^{2}\text{Var}(X)$
표준화 확률 변수(Standardized Random Variable)
- 확률 변수 `X` 의 평균 `μ` 와 표준 편차 `σ` 에 대해 확률 변수 $\displaystyle Z = \frac{X - μ}{σ}$ 를 `X` 의 표준화 확률 변수(Standardized Random Variable)라 한다.
- 그러면 표준화 확률 변수의 평균과 분산은 각각 다음과 같다.
$$E(Z) = \frac{1}{σ}X - \frac{μ}{σ} = \frac{1}{σ}E(X) - \frac{μ}{σ} = 0 \\ \text{Var}(Z) = \text{Var}(\frac{1}{σ}X - \frac{μ}{σ}) = \frac{1}{σ^{2}} \text{Var(X)} = 1$$
예제 : 연속 확률 변수 `X` 의 확률 밀도 함수가 $\displaystyle f(x) = \frac{3}{8}x^{2}, \; 0 \le x \le 2$ 일 때, 확률 변수 `X` 의 분산과 표준 편차를 구하라.
(1) $μ(E(X))$ 구하기
$\displaystyle μ = E(X) = \int_{-\infty}^{\infty} xf(x)dx = \frac{3}{8} \int_{0}^{2}x^{3}dx = \left [ \frac{3}{32}x^{4} \right ]^{2}_{0} = \frac{3}{2}$
(2) $μ(E(X^{2}))$ 구하기
$\displaystyle E(X^{2}) = \int_{-\infty}^{\infty} x^{2}f(x)dx = \frac{3}{8} \int_{0}^{2} x^{4}dx = \left [\frac{3}{40} x^{5} \right ]^{2}_{0} = \frac{12}{5}$
따라서 확률 변수 `X` 의 분산 $σ^{2}$ 과 표준 편차 `σ` 를 구하면 각각 다음과 같다.
$\displaystyle σ^{2} = E(X^{2}) - μ^{2} = \frac{12}{5} - \left( \frac{3}{2} \right)^{2} = \frac{3}{20}, \quad σ = \sqrt{\frac{3}{20}} ≒ 0.3878$
'Mathematics > 확률과 통계' 카테고리의 다른 글
| [확률과 통계] 모평균의 추정 (0) | 2022.11.27 |
|---|---|
| [확률과 통계] 모집단과 표본 (0) | 2022.11.21 |
| [확률과 통계] 연속 확률 분포 (0) | 2022.11.21 |
| [확률과 통계] 이산 확률 분포 (0) | 2022.11.14 |
| [확률과 통계] 연속 확률 변수 (0) | 2022.11.14 |
| [확률과 통계] 이산 확률 변수 (0) | 2022.11.07 |
| [확률과 통계] 베이즈 정리 (0) | 2022.10.31 |
| [확률과 통계] 조건부 확률 (0) | 2022.10.31 |