


백트래킹(Backtracking)
개념
- 모든 경우의 수를 고려하는 알고리즘
- 상태 공간을 트리(Tree)로 나타낼 수 있을 때 적합한 방식이다.
- 일종의 트리 탐색 알고리즘(Tree Search Algorithm)이라고 봐도 된다.
- 방식에 따른 분류
- 깊이 우선 탐색(Depth First Search, DFS)
- 너비 우선 탐색(Breadth First Search, BFS)
- 최선 우선 탐색(Best First Search / Heuristic Search)
- 경우의 수 구하기는 일반적으로 DFS가 편리하며, 대다수의 문제들은 DFS를 써도 일단 답은 나온다.
- 하지만, 트리의 깊이(Depth)가 무한대가 될 경우에는 DFS를 사용하면 안된다.
- 예) 미로 찾기에서 루프(회로)가 발생하는 경우, DFS는 이 가지를 탈출할 수 없게 된다.
- 중복 검사를 막기 위한 장치를 넣을 수도 있지만, 그럴 바에는 BFS를 사용하는 것이 편리하다.
- 분기점 없이 긴 길이가 나타나면 스택 오버플로우(Stack Overflow)가 발생할 수 있다.
- 예) 미로 찾기에서 4방향(또는 8방향) 중 마지막으로 진입하는 방향으로만 갔을 때 도착점이 있다거나 하면 DFS는 느리다.
- 하지만, 트리의 깊이(Depth)가 무한대가 될 경우에는 DFS를 사용하면 안된다.
- 최단 거리 구하기에는 BFS를 사용하는 것이 편리하다.
- 일반적으로 DFS는 백트래킹 알고리즘 등에 사용되며, BFS는 그래프의 최단 경로 구하기 문제 등에 사용된다.
깊이 우선 탐색(Depth First Search, DFS)
개념
- 상태 공간을 나타낸 트리에서 바닥에 도달할 때까지 한 쪽 방향으로만 내려가는 방식
- 예) 미로 찾기
- 한 방향으로 들어갔다가 막 다른 길에 다다르면(=트리의 바닥에 도착) 왔던 길을 돌아가서 다른 방향으로 간다.
- 이것을 목표 지점(=원하는 해)이 나올 때까지 반복한다.
- 재귀 함수(Recursion) 또는 스택(Stack)을 써서 구현할 수 있다.
- 코딩 테스트에서는 재귀 함수를 이용한 구현이 더 선호되는 편이다.
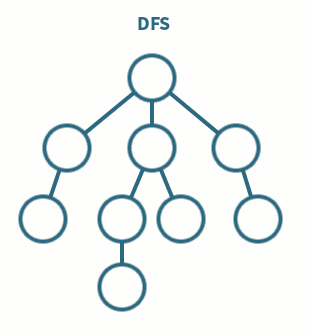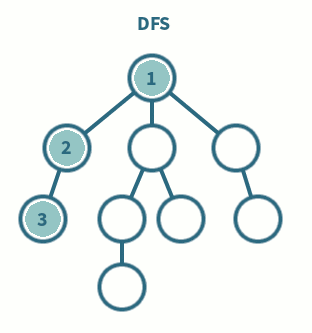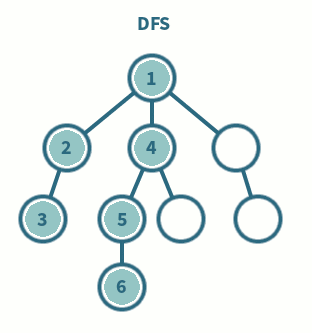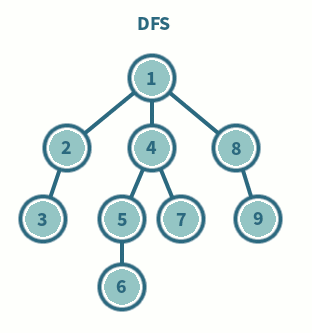
백트래킹과 DFS
- DFS는 가능한 모든 경로(후보)를 탐색하므로, 불필요할 것 같은 경로를 사전에 차단하는 등의 행동이 없으므로 경우의 수를 줄이지 못한다.
- 따라서 `N!` 가지의 경우의 수를 가진 문제는 DFS로 처리가 불가능하다.
- 백트래킹(Backtracking)은 해를 찾아가는 도중, 지금의 경로가 해가 될 것 같지 않으면 그 경로를 더이상 가지 않고 되돌아간다. 따라서 반목문의 횟수까지 줄일 수 있으므로 효율적이다.
- 이것을 가지치기(Prunning)라고 하는데, 불필요한 부분을 쳐내고 최대한 올바른 쪽으로 간다는 의미이다.
- 일반적으로 불필요한 경로를 조기에 차단할 수 있게 되어 경우의 수가 줄어들지만, `N!` 의 경우의 수를 가진 문제에서 최악의 경우에는 여전히 지수 함수 시간을 필요로 하므로 처리가 불가능할 수 있다.
- 가지치기를 얼마나 잘하느냐에 따라 효율성이 결정된다.
- 따라서 백트래킹은 모든 가능한 경우의 수 중에서 특정한 조건을 만족하는 경우만 살펴보는 것이라고 할 수 있다.
- 답이 될 만한지 판단하고, 그렇지 않으면 그 부분까지 탐색하는 것을 하지 않고 가지치기 하는 것을 백트래킹이라고 할 수 있다.
- 주로 문제 풀이에서는 DFS 등으로 모든 경우의 수를 탐색하는 과정에서, 조건문 등을 걸어 답이 절대로 될 수 없는 상황을 정의하고, 그렇나 상황일 경우에는 탐색을 중지시킨 뒤 그 이전으로 돌아가서 다시 다른 경우를 탐색하게끔 구현할 수 있다.
- 어떤 노드의 유망성, 즉 해가 될 만한지 판단한 후 유망하지 않다고 결정되면 그 노드의 이전(부모)로 돌아가(Backtracking) 다음 자식 노드로 간다.
- 해가 될 가능성이 있으면 유망하다(Promising)고 하며, 유망하지 않은 노드에 가지 않는 것을 가지치기(Prunning)한다고 한다.
구현
- 스택(Stack)이나 재귀 함수(Recursion), 노드 방문 여부를 표시하기 위한 컨테이너(isVisited)를 이용하여 구현한다.
- 일반적으로 DFS는 스택(Stack)으로 구현되며, 재귀를 이용하면 좀 더 간단하게 구현할 수 있다.
- 실제로 코딩 테스트에서는 재귀를 이용한 구현이 더 선호되는 편이다.
① 재귀 함수(Recursion)를 이용한 구현
슈도 코드(Pseudo Code)
RecursiveDFS(v)
mark v as visited node
for each edge (v, w)
if w is unmarked :
RecursiveDFS(w)
파이썬(Python) 코드
- 재귀 함수로 구현할 경우, 모든 정점을 사전순(A→B→C)로 방문하게 된다.
def RecursiveDFS(v, visited=[])
visited.append(v)
for w in graph[v] :
if not w in visited :
visited = RecursiveDFS(w, visited)
return visited
C++ 코드
vector<int> adjList[101];
bool isVisited[101];
void RecursiveDFS(int v) {
if (isVisited[v]) return; // 이미 방문했을 경우
isVisited[v] = true; // 방문 표시
cout << v << " "; // 방문한 노드 출력
for (int i = 0; i < adjList[v].size(); i++) {
int next = adjList[v][i];
RecursiveDFS(next);
}
}
② 스택(Stack)을 이용한 구현
슈도 코드(Pseudo Code)
IterativeDFS(s)
stack.push(s)
while stack is not empty
v = stack.pop()
if v is unmarked :
mark v as visited node
for each edge v → w
if w is unmarked :
stack.push(w)
파이썬(Python) 코드
- 스택을 이용하여 구현할 경우, 재귀 구조에 비해 코드의 간결성은 떨어지지만 실행 속도가 더 빠르다.
- 또한 스택을 이용할 경우, 모든 정점을 역순(C→B→A)으로 방문하게 된다.
def IterativeDFS(s):
visited = []
stack = [s]
while stack:
v = stack.pop()
if v not in visited :
visited.append(v)
for w in graph[v] :
stack.append(w)
return visited
C++ 코드
vector<int> adjList[101];
bool isVisited[101];
stack<int> stk;
void IterativeDFS(int v) {
stk.push(v); // 루트 노드 삽입
while (!stk.empty()) {
int current = stk.top();
stk.pop();
if (isVisited[current]) continue; // 방문되었을 경우 다음으로 넘어간다.
isVisited[current] = true; // 방문 표시
cout << current << " "; // 방문한 노드 출력
for (int i = 0; i < adjList[current].size(); i++) {
int next = adjList[current][i];
stk.push(next);
}
/* 사전순 출력
for (int i = adjList[current].size() - 1; i >= 0; i--) {
int next = adjList[current][i];
stk.push(next);
}
*/
}
}
너비 우선 탐색(Breadth First Search, BFS)
개념
- 모든 분기점을 다 검사하면서 진행하는 방식
- 다음과 같은 문제에서 효과를 발휘한다.
- 예) 철수와 영희가 계단에서 가위바위보를 하며 게임을 하고 있을 때, 철수가 원하는 지점에 갈 수 있는 최소 승리 횟수는 얼마인가?
- DFS를 사용할 경우, 깊이가 무한인 경우에 빠져나오지 못하며, 중복 방지를 한다고 하더라도 올바른 해를 찾는데 시간이 많이 걸린다.
- BFS는 모든 분기를 다 검색하면서 상태 공간을 탐색한다.
- 철수가 이겼을 때(W), 비겼을 때(D), 졌을 때(L)를 검사하고, 그 경우마다 각각 또 다른 3가지 가능성(W/D/L)을 전부 검사한다.
- 이러다가 어느 한 부분에서 원하는 해를 발견하면, 이것이 최단 거리가 된다.
- 최단 경로를 찾는 문제나 임의의 경로를 찾는 문제, 다익스트라 알고리즘 등에서 유용하게 사용된다.
- 예) 철수와 영희가 계단에서 가위바위보를 하며 게임을 하고 있을 때, 철수가 원하는 지점에 갈 수 있는 최소 승리 횟수는 얼마인가?
- 큐(Queue)를 써서 구현할 수 있다.
- 각 경우를 검사하면서 발생하는 새로운 경우를 큐에 집어 넣고, 검사한 원소는 큐에서 뺀다.
- DFS가 못건드리는 문제를 풀 수 있다는 장점이 있지만, 공간 복잡도가 지수 스케일로 폭발하기 때문에 가지치기를 제대로 안하면 DFS 보다 오버 플로우(Overflow)에 다다를 수 있다.
- 프림(Prime) 알고리즘 및 다익스트라(Dijkstra) 알고리즘과 유사하다.
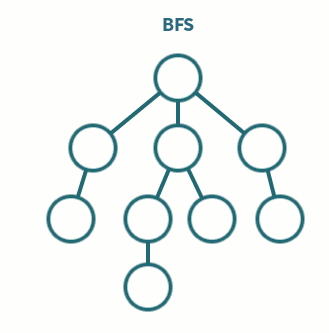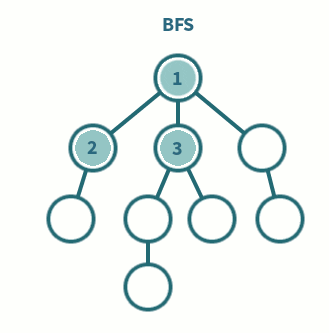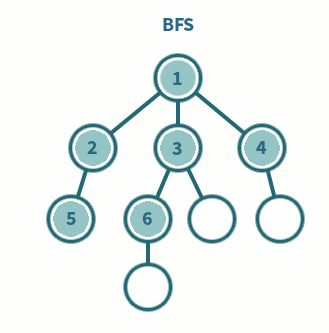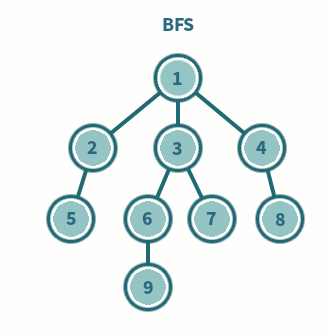
구현
- 큐(Queue)와 노드 방문 여부를 표시하기 위한 컨테이너(isVisited)를 이용하여 구현한다.
큐(Queue)를 이용한 구현
- DFS와 달리 재귀로 동작하지 않기 때문에 큐(Queue)를 이용한 반복 구조로만 구현이 가능하다.
슈도 코드(Pseudo Code)
BFS(s):
mark s as visited node
Q.enqueue(s)
while Q is not empty:
v = Q.dequeue()
for each edge v → w:
if w is unmarked :
mark v as visited node
Q.enqueue(w)
# w.parent = v
# w.dist = v.dist + 1
파이썬(Python) 코드
def IterativeBFS(s):
visited = [s]
queue = [s]
while queue :
v = queue.pop(0) # v = deque.popleft()
for w in graph[v] :
if w not in visited :
visited.append(w)
queue.append(w)
return visited
C++ 코드
vector<int> adjList[101];
bool isVisited[101];
queue<int> que;
void IterativeBFS(int v) {
que.push(v); // 루트 노드 삽입
while (!que.empty()) {
int current = que.front();
que.pop();
if (isVisited[current]) continue; // 방문되었을 경우 다음으로 넘어간다.
isVisited[current] = true; // 방문 표시
cout << current << " "; // 방문 노드 출력
for (int i = 0; i < adjList[current].size(); i++) {
int next = adjList[current][i];
que.push(next);
}
}
}
최선 우선 탐색(Best First Search / Heuristic Search)
개념
- BFS에서 조금 더 발전한 방식으로, 큐(Queue) 대신 보통 힙(Heap)으로 구현되는 우선순위 큐(Priority Queue)를 써서 구현할 수 있다.
- 후보중에서 어떤 경로를 확장하는 것이 가장 좋은가 하는 효율적인 선택은 일반적으로는 우선순위 큐를 사용하여 구현된다.
- 발생하는 새로운 경우를 순차적으로 검사하는 BFS와 달리, 현재 가장 최적인 경우를 우선적으로 검사하므로 상대적으로 효율적이다.
- 백트래킹은 모든 경우를 다 고려하기 때문에, 이 방법을 쓰면 왠만하면 문제를 해결할 수 있다.
- 다이나믹 프로그래밍(DP)으로 할 수 있는 것을 전부 구현 가능하다.
- 시간과 메모리만 해결하면 매우 유용한 방법이다.
- 문제를 해결하지 못한다면 그 이유는 시간이 많이 걸려서이다.
- 무의미한 탐색을 막아줄 가지치기(Bounded(Promising) Function)를 적용하여 적당한 지능(Heuristic)을 부여한다면 상당히 효과적인 해결 방법이 될 수 있다.
- 예) 철수와 영희의 문제의 경우, 목적 지점과 계속 반대로 가려는 가지는 굳이 탐색할 필요가 없으므로, 적절히 쳐내면 된다.
- 전혀 가망이 없는 경우로의 탐색이 이루어지지 않으므로 계산 성능이 향상된다.
- 가지치기 연습 문제 : 공주님의 정원(백준)
- 예) 철수와 영희의 문제의 경우, 목적 지점과 계속 반대로 가려는 가지는 굳이 탐색할 필요가 없으므로, 적절히 쳐내면 된다.
2457번: 공주님의 정원
첫째 줄에는 꽃들의 총 개수 N (1 ≤ N ≤ 100,000)이 주어진다. 다음 N개의 줄에는 각 꽃이 피는 날짜와 지는 날짜가 주어진다. 하나의 날짜는 월과 일을 나타내는 두 숫자로 표현된다. 예를 들어서,
www.acmicpc.net
- 최선 우선 탐색 알고리즘의 예로 다익스트라 알고리즘과 A* 알고리즘이 있다.
- 최선 우선 탐색 알고리즘은 조합 탐색(Combinatorial Search)에서 발견(Pathfinding)을 위해서도 가끔 사용된다.
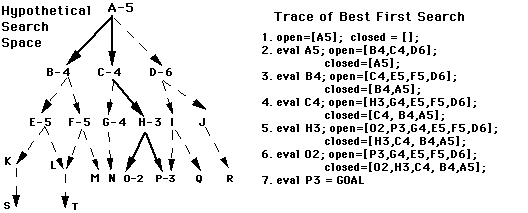
구현
우선순위 큐(Priority Queue)를 이용한 구현
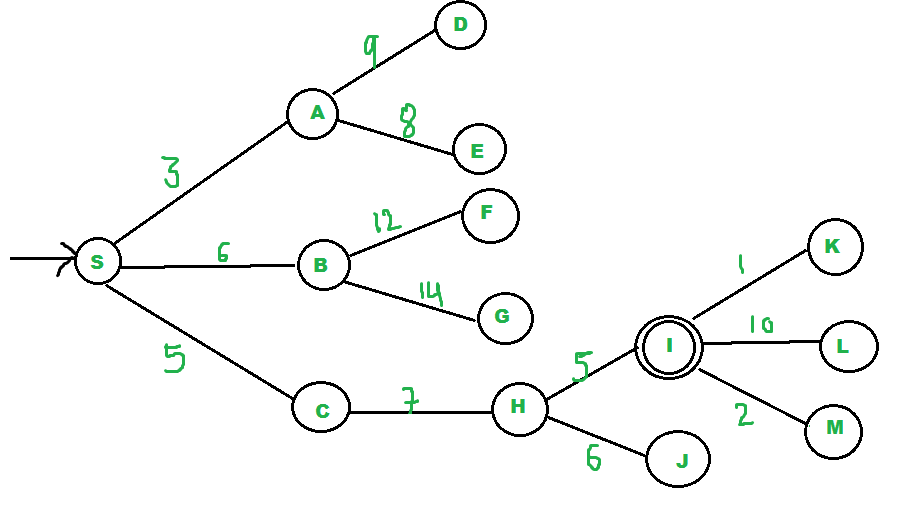
We start from source “S” and search for goal “I” using given costs and Best First search.
- pq initially contains S
> We remove s from and process unvisited neighbors of S to pq.
> pq now contains {A, C, B} (C is put before B because C has lesser cost)
- We remove A from pq and process unvisited neighbors of A to pq.
> pq now contains {C, B, E, D}
- We remove C from pq and process unvisited neighbors of C to pq.
> pq now contains {B, H, E, D}
- We remove B from pq and process unvisited neighbors of B to pq.
> pq now contains {H, E, D, F, G}
- We remove H from pq.
- Since our goal “I” is a neighbor of H, we return.
슈도 코드(Pseudo Code)
Best-First-Search(Graph g, Node start)
1) Create an empty PriorityQueue
PriorityQueue pq;
2) Insert "start" in pq.
pq.insert(start)
3) Until PriorityQueue is empty
u = PriorityQueue.DeleteMin
If u is the goal
Exit
Else
Foreach neighbor v of u
If v "Unvisited"
Mark v "Visited"
pq.insert(v)
Mark u "Examined"
파이썬(Python) 코드
def BestFirstSearch(actual_Src, target, n):
visited = [False] * n
pq = PriorityQueue()
pq.put((0, actual_Src))
visited[actual_Src] = True
while pq.empty() == False:
u = pq.get()[1]
# Displaying the path having lowest cost
print(u, end=" ")
if u == target:
break
for v, c in graph[u]:
if visited[v] == False:
visited[v] = True
pq.put((c, v))
C++ 코드
void BestFirstSearch(int actual_Src, int target, int n) {
vector<bool> visited(n, false);
// MIN HEAP priority queue
priority_queue<pi, vector<pi>, greater<pi> > pq;
// sorting in pq gets done by first value of pair
pq.push(make_pair(0, actual_Src));
int s = actual_Src;
visited[s] = true;
while (!pq.empty()) {
int x = pq.top().second;
// Displaying the path having lowest cost
cout << x << " ";
pq.pop();
if (x == target)
break;
for (int i = 0; i < graph[x].size(); i++) {
if (!visited[graph[x][i].second]) {
visited[graph[x][i].second] = true;
pq.push(make_pair(graph[x][i].first,graph[x][i].second));
}
}
}
}
사용 예
#include <iostream>
#include <stack>
#include <queue>
#include <vector>
#include <algorithm>
using space std;
vector<int> adjList[101];
bool isVisited[101];
stack<int> stk;
queue<int> que;
void RecursiveDFS(int v) {
if (isVisited[v]) return; // 이미 방문했을 경우
isVisited[v] = true; // 방문 표시
cout << v << " "; // 방문한 노드 출력
for (int i = 0; i < adjList[v].size(); i++) {
int next = adjList[v][i];
RecursiveDFS(next);
}
}
void IterativeDFS(int v) {
stk.push(v); // 루트 노드 삽입
while (!stk.empty()) {
int current = stk.top();
stk.pop();
if (isVisited[current]) continue; // 방문되었을 경우 다음으로 넘어간다.
isVisited[current] = true; // 방문 표시
cout << current << " "; // 방문한 노드 출력
for (int i = 0; i < adjList[current].size(); i++) {
int next = adjList[current][i];
stk.push(next);
}
/* 사전순 출력
for (int i = adjList[current].size() - 1; i >= 0; i--) {
int next = adjList[current][i];
stk.push(next);
}
*/
}
}
void IterativeBFS(int v) {
que.push(v); // 루트 노드 삽입
while (!que.empty()) {
int current = que.front();
que.pop();
if (isVisited[current]) continue; // 방문되었을 경우 다음으로 넘어간다.
isVisited[current] = true; // 방문 표시
cout << current << " "; // 방문 노드 출력
for (int i = 0; i < adjList[current].size(); i++) {
int next = adjList[current][i];
que.push(next);
}
}
}
int main() {
int N, M, S; // 노드 수 : N, 간선 수 : M, 시작 노드 : S
cin >> N >> M >> S;
for (int i = 0; i < M; i++) {
int from, to;
cin >> from >> to;
adjList[from].push_back(to);
adjList[to].push_back(from);
}
// 정렬 수행
for (int i = 0; i < 101; i++) {
sort(adjList[i].begin(), adjList[i].end());
}
cout << "Recursive DFS" << endl;
fill_n(isVisited, 101, false); // 방문 여부 초기화
RecursiveDFS(S);
cout << endl;
cout << "Iterative DFS" << endl;
fill_n(isVisited, 101, false); // 방문 여부 초기화
IterativeDFS(S);
cout << endl;
cout << "Iterative BFS" << endl;
fill_n(isVisited, 101, false); // 방문 여부 초기화
IterativeBFS(S);
return 0;
}
백트래킹 알고리즘을 사용할 때의 시간 복잡도
- $N^{N}$ : 중복이 가능, N = 8까지 가능
- [깊이 0] 1 ~ n : N
- [깊이 1] 1 ~ n : N
- [깊이 2] 1 ~ n : N
- ...
- 시간 복잡도는 $N × N × N ... × N = N × N = N^{N}$ 이다.
- $N!$ : 중복이 불가, N = 10까지 가능
- [깊이 0] 1 ~ n : N
- [깊이 1] 1 ~ n - 1 : N - 1
- [깊이 2] 1 ~ n - 2 : N - 2
- ...
- 시간 복잡도는 $N × (N - 1) × (N - 2) × ... × 1 = N!$ 이다.
- 따라서 백트래킹을 사용할 경우 최대 N = 10까지 사용 가능하다. (입력 조건을 확인하고 사용한다.)
관련 문제
[BOJ-15649][C++] N과 M (1)
문제 자연수 N과 M이 주어졌을 때, 아래 조건을 만족하는 길이가 M인 수열을 모두 구하는 프로그램을 작성하시오. 1부터 N까지 자연수 중에서 중복 없이 M개를 고른 수열 입력 첫째 줄에 자연수 N
dev-astra.tistory.com
[BOJ-15650][C++] N과 M (2)
문제 자연수 N과 M이 주어졌을 때, 아래 조건을 만족하는 길이가 M인 수열을 모두 구하는 프로그램을 작성하시오. 1부터 N까지 자연수 중에서 중복 없이 M개를 고른 수열 고른 수열은 오름차순이
dev-astra.tistory.com
[BOJ-15651][C++] N과 M (3)
문제 자연수 N과 M이 주어졌을 때, 아래 조건을 만족하는 길이가 M인 수열을 모두 구하는 프로그램을 작성하시오. 1부터 N까지 자연수 중에서 M개를 고른 수열 같은 수를 여러 번 골라도 된다. 입
dev-astra.tistory.com
[BOJ-15652][C++] N과 M (4)
문제 자연수 N과 M이 주어졌을 때, 아래 조건을 만족하는 길이가 M인 수열을 모두 구하는 프로그램을 작성하시오. 1부터 N까지 자연수 중에서 M개를 고른 수열 같은 수를 여러 번 골라도 된다. 고
dev-astra.tistory.com
참고 사이트
'Computer Science > 알고리즘' 카테고리의 다른 글
| [Algorithm] 이항 계수(Binomial Coefficient) (0) | 2022.11.15 |
|---|---|
| [Algorithm] 최대 공약수(GCD)와 최소 공배수(LCM) ; 유클리드 호제법(Euclidean Algorithm) (0) | 2022.11.13 |
| [Algorithm] 브루트 포스(Brute Force) (0) | 2022.11.03 |
| [Algorithm] 하노이 탑(Tower of Hanoi) (0) | 2022.11.03 |
| [Algorithm] 스캐닝 메소드(Scanning Method) (0) | 2022.10.26 |
| [Algorithm] 부분합(Partial Sum) ; 누적합(Prefix Sum) (0) | 2022.10.26 |
| [Algorithm] 형상수(Figulate Number) (0) | 2022.10.26 |
| [Algorithm] 에라토스테네스의 체(Sieve of Erathosthenes) (0) | 2022.10.25 |