


728x90
산포도
산포도(Measure of Dispersion)
- 두 자료 집단의 대푯값인 평균이 동일하더라도, 두 자료 집단의 특성이 동일한 것은 아니다.
예
자료 집단 A : [1 2 3 4 5 5 5 6 7 8 8 9 9 9 9]
자료 집단 B : [4 5 5 5 6 6 6 6 6 6 6 7 7 7 8]
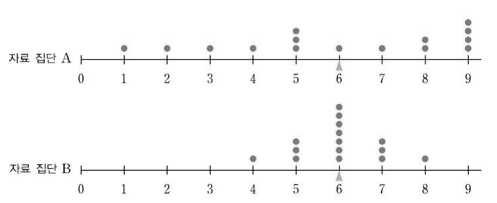
- 두 자료 집단의 평균은 동일하게 6이지만, 점도표를 그리면 명확하게 다르다는 사실을 알 수 있다.
- 자료 집단 A는 오른쪽으로 치우치고 왼쪽으로 길게 퍼지는 형태이지만, 자료 집단 B는 평균 6을 중심으로 집중되는 형태이다.
- 따라서 수집한 자료의 분포를 충분히 설명하기 위해 대푯값 이외에 자료가 흩어져 있는 정도에 대한 척도가 필요하며, 이와 같이 흩어진 정도를 나타내는 척도를 산포도(Measure of Dispersion)라 한다.
범위(Range)
- 자료값의 흩어진 모양이 평균을 중심으로 어느 정도 대칭성이 있는 경우에 사용하는 가장 간단한 형태의 산포도
- 자료를 크기순으로 재배열하여 $x_{(1)}, x_{(2)}, \cdots, x_{(n)}$ 이라 하자.
수집한 자료의 가장 큰 측정값과 가장 작은 측정값의 차이를 의미하며, $R = x_{(n)} - x_{(1)}$ 로 표현한다.
예
- 자료 A [1 2 3 4 5] 와 자료 B [1 2 3 4 50] 의 범위는 각각 $R_{A} = 4(5 -1), \; R_{B} = 49(50 - 1)$ 이다.
- 최댓값이 5인 경우와 50인 경우에 대해 범위는 크게 차이가 난다.
- 따라서 범위는 계산하기 쉽지만, 특이값의 유무에 따라 크게 영향을 받는다.
- 또한, 최댓값과 최솟값만을 이용하므로 범위가 동일하더라도 자료 집단의 분포 모양은 다를 수 있다.
범위의 특징
- 계산이 쉽다.
- 특이값(극단적인 값)의 영향을 많이 받는다.
- 각각의 측정값에 대한 정보를 반영하지 못한다.
- 자료의 개수가 많으면 부적절하다.
- 범위가 동일해도 분포가 다를 수 있다.
평균 편차(Mean Deviation)
각 자료의 측정값과 평균과의 편차에 대한 절댓값들의 평균
$$M.D = \frac{1}{n} \sum_{i=1}^{n} | x_{i} - \overline{x} |$$
예 : 표본 [3 4 6 7 7 9]의 평균 편차 구하기
우선 자료 3, 4, 6, 7, 7, 9 의 평균을 구하면 다음과 같다.
$\displaystyle \overline{x} = \frac{1}{6}(3 + 4 + 6 + 7 + 7+ 9) = 6$
따라서 각 자료값의 편차와 그 절댓값을 구하면 다음과 같다.
자료 3 4 6 7 7 9 평균과의 편차 -3(3-6) -2(4-6) 0(6-6) 1(7-6) 1(7-6) 3(9-3) 편차 절댓값 3 2 0 1 1 3
따라서 평균 편차는 $\displaystyle M.D = \frac{1}{6}(3 + 2 + 0 + 1 + 1 + 3) ≒ 1.67$ 이다.
평균 편차의 특징
- 개개의 측정값에 대한 정보가 반영된다.
- 특이값에 대한 영향을 범위보다는 적게 받는다.
- 평균 편차가 클수록 폭넓은 분포가 형성된다.
분산(Variance)
- 대푯값으로 평균을 사용할 때 널리 사용하는 산포도
- 모분산(Population Variance) : 모집단을 구성하는 모든 자료값과 모평균의 편차의 제곱합에 대한 평균
- 표본 분산(Sample Variance) : 표본을 구성하는 모든 자료값과 표본 평균의 편차의 제곱합을 $\it \color{red} {n - 1}$ 로 나눈 수치
- 크기가 `N` 인 모분산과 크기가 `n` 인 표본 분산은 각각 다음과 같이 구한다.
모분산 : $\displaystyle σ^{2} = \frac{1}{N} \sum_{i=1}^{N}(x_{i} - μ)^{2}$ (`μ` : 모평균)
표본 분산 : $\displaystyle s^{2} = \frac{1}{\color{red}{n-1}} \sum_{i=1}^{n}(x_{i} - \overline{x})^{2}$ ($\overline{x}$ : 표본 평균)
예 : 표본 [3 4 6 7 7 9]의 표본 분산 구하기
우선 자료 3, 4, 6, 7, 7, 9 의 평균을 구하면 다음과 같다.
$\displaystyle \overline{x} = \frac{1}{6}(3 + 4 + 6 + 7 + 7+ 9) = 6$
따라서 각 자료값의 편차와 그 절댓값을 구하면 다음과 같다.
자료 3 4 6 7 7 9 평균과의 편차 -3(3-6) -2(4-6) 0(6-6) 1(7-6) 1(7-6) 3(9-3) 편차 제곱 9 4 0 1 1 9
표본의 크기 `n = 6` 이므로, 분산을 구하면 $\displaystyle s^{2} = \frac{1}{6 - 1}(9 + 4 + 0 + 1 + 9) = 4.8$ 이다.
분산의 특징
- 개개의 측정값에 대한 정보가 반영된다.
- 수리적으로 다루기 쉽다.
- 특이값(극단적인 값)의 영향을 매우 크게 받는다.
- 분산이 클수록 평균으로부터 넓은 분포가 형성된다.
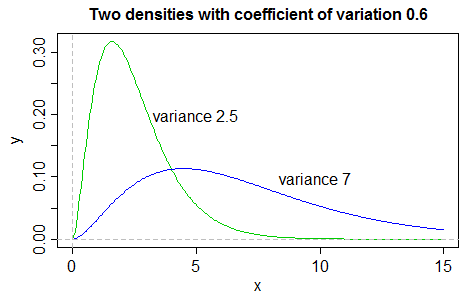
표준 편차(Standard Deviation)
- 분산은 개개의 자료값에 대한 평균 편차의 제곱에 의해 정의되므로, 분산의 단위는 자료값의 단위를 제곱한 단위이다.
- 예) 키의 단위로 cm 를 사용하면, 분산의 단위는 cm² 이 된다.
- cm² 단위는 통상적으로 넓이를 나타내므로 자료의 특성을 분석할 때 혼란이 생긴다.
- 예) 키의 단위로 cm 를 사용하면, 분산의 단위는 cm² 이 된다.
- 따라서 자료값의 단위와 동일한 척도를 이용할 필요가 있으며, 이를 위해 분산의 양의 제곱근을 택한다.
모 표준 편차(Population Standard Deviation) : 모분산의 양의 제곱근
표본 표준 편차(Sample Standard Deviation) : 표본 분산의 양의 제곱근
- 표준 편차는 분산과 같은 성질을 가지며, 다음과 같이 구한다.
모 표준 편차 : $\displaystyle σ = \sqrt{\frac{1}{N} \sum_{i=1}^{N}(x_{i} - μ)^{2}}$
표본 표준 편차 : $\displaystyle s = \sqrt{\frac{1}{n-1} \sum_{i=1}^{n}(x_{i} - \overline{x})^{2}}$
예 : 표본 [3 4 6 7 7 9]의 표본 표준 편차 구하기 (소수점 이하 둘째 자리까지)
우선 자료 3, 4, 6, 7, 7, 9 의 평균을 구하면 다음과 같다.
$\displaystyle \overline{x} = \frac{1}{6}(3 + 4 + 6 + 7 + 7+ 9) = 6$
따라서 각 자료값의 편차와 그 절댓값을 구하면 다음과 같다.
자료 3 4 6 7 7 9 평균과의 편차 -3(3-6) -2(4-6) 0(6-6) 1(7-6) 1(7-6) 3(9-3) 편차 제곱 9 4 0 1 1 9
표본의 크기 `n = 6` 이므로, 분산을 구하면 $\displaystyle s^{2} = \frac{1}{6 - 1}(9 + 4 + 0 + 1 + 9) = 4.8$ 이다.
$s^{2} = 4.8$ 이므로 표준 편차는 $s = \sqrt{4.8} ≒ 2.19$ 이다.
표준 편차의 특징
- 표준 편차가 클수록 평균으로부터 넓은 분포가 형성된다.
 |
 |
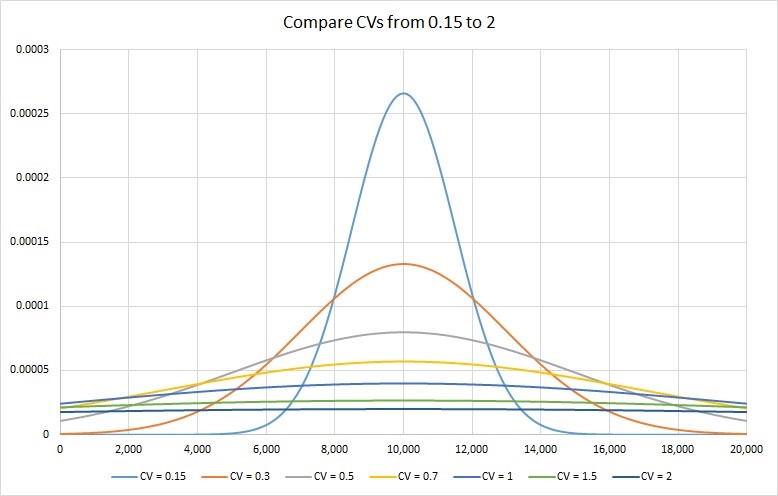
변동 계수(Coefficient of Variation)
표준 편차를 평균으로 나눈 백분율
- 표준 편차는 평균을 중심으로 자료가 밀집되거나 흩어진 정도를 절대적인 수치로 나타낸 산포도이다.
- 그러나 측정 단위가 서로 다른 몸무게와 키에 대한 산포를 비교하거나, 코끼리의 몸무게와 강아지의 몸무게와 같이 측정 단위가 동일하더라도 평균의 차이가 극심한 경우에 산포도를 절대적인 수치로 비교하는 것은 곤란하다.
- 따라서 두 자료 집단의 산포도를 상대적으로 비교하는 산포도가 필요하며, 변동 계수가 이에 해당한다.
- 모집단과 표본의 변동 계수는 각각 다음과 같이 구한다.
모집단의 변동 계수 : $\displaystyle C.V_{p} = \frac{σ}{μ} × 100(\%)$ (`μ` : 모평균)
표본의 변동 계수 : $\displaystyle C.V_{s} = \frac{s}{\overline{x}} × 100(\%)$ ($\overline{x}$ : 표본 평균)
예 : 두 표본 A [171 164 167 156 159 164], B [11.5 12.2 12.0 12.4 13.6 10.5]에 대해 어느 표본이 평균으로부터 상대적으로 더 넓게 분포하는지 결정하기
두 표본 A와 B의 평균을 $\overline{x}, \overline{y}$ 라 하고, 표준 편차를 $s_{A}, s_{B}$ 라 하면,
$\displaystyle \overline{x} = \frac{171 + 164 + 167 + 156 + 159 + 164}{6} = 163.5$
$\displaystyle \overline{y} = \frac{11.5 + 12.2 + 12 + 12.4 + 13.6 + 10.5}{6} ≒ 12$
$\displaystyle s^{2}_{A} = \frac{1}{5} \sum(x - 163.5)^{2} = 29.1$
$\displaystyle s_{A} = \sqrt{29.1} ≒ 5.39$
$\displaystyle s^{2}_{B} = \frac{1}{5} \sum(x - 12)^{2} = 1.052$
$\displaystyle s_{B} = \sqrt{1.052} ≒ 1.026$
이다. 따라서 두 표본의 변동 계수를 구하면 각각 다음과 같다.
$\displaystyle C.V_{A} = \frac{5.39}{163.5} ≒ 0.033, \quad C.V_{B} = \frac{1.026}{12} ≒ 0.0855$
그러므로 절대 수치에 의하면 표본 A의 분포가 표본 B에 비해 폭넓게 나타나지만($s^{2}_{A} > s^{2}_{B}$ 이므로), 상대적으로 비교하면 표본 B의 분포가 표본 A에 비해 폭넓게 나타난다. ($C.V_{A} < C.V_{B}$ 이므로)
변동 계수의 특징
- 변동 계수가 클수록 평균으로부터 넓은 분포가 형성된다.
728x90
'Mathematics > 확률과 통계' 카테고리의 다른 글
| [확률과 통계] 확률 (0) | 2022.10.31 |
|---|---|
| [확률과 통계] 시행과 사건 (0) | 2022.10.31 |
| [확률과 통계] 도수 분포표에서의 평균과 분산 (1) | 2022.10.11 |
| [확률과 통계] 위치 척도와 상자 그림 (0) | 2022.10.11 |
| [확률과 통계] 대푯값 (0) | 2022.10.10 |
| [확률과 통계] 양적 자료의 정리 (0) | 2022.10.04 |
| [확률과 통계] 질적 자료의 정리 (0) | 2022.10.04 |
| [확률과 통계] 자료의 종류 (0) | 2022.10.03 |