


728x90
애저(Azure) Machine Learning Service의 Designer 사용해보기
들어가며
- Azure의 Machine Learning Service를 배포해보고, Desginer를 이용하여 실습해보자.
실습하기
Azure Machine Learning 서비스 만들기
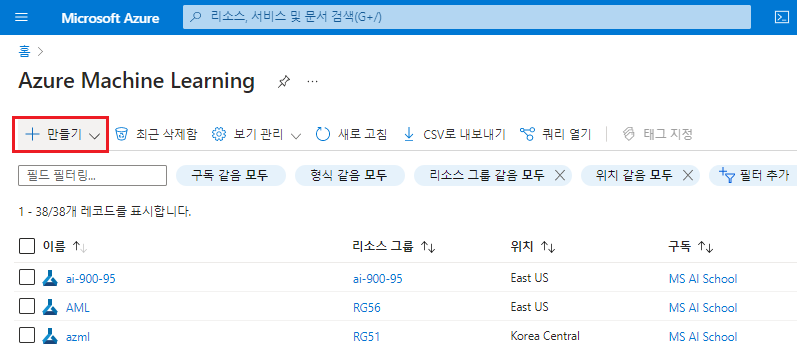
- 애저 포털의 검색창에 @Azure Machine Learning@을 검색한 후 @[Azure Machine Learning]@ 서비스로 진입한다.

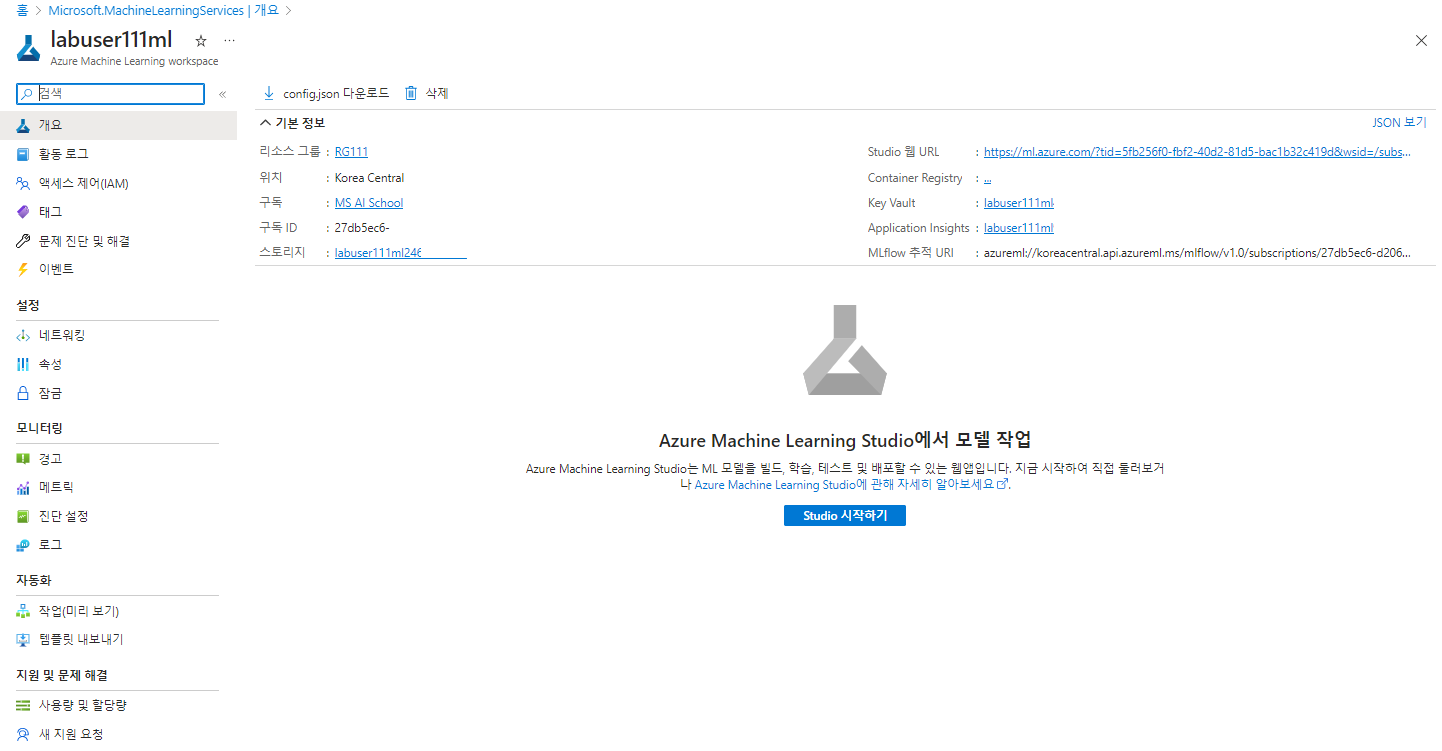
- @[Azure Machine Learning]@ 페이지에서 @[만들기]@ 버튼을 클릭하여 리소스를 만들어준다.
 |
 |
 |
 |
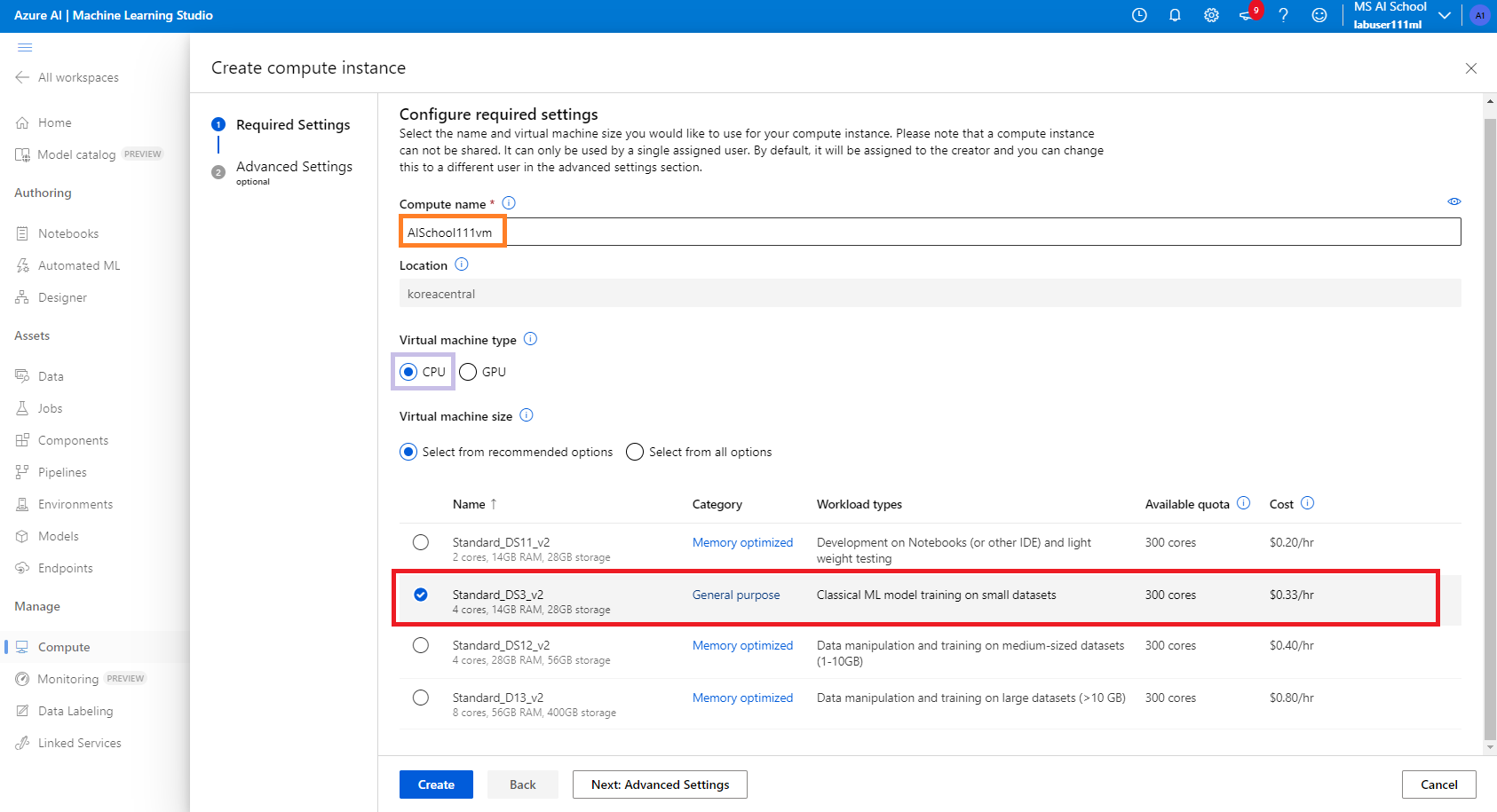
Azure Machine Learning Studio 페이지에서 가상 머신 생성하기
- 별도의 포탈에 진입해야 한다. @[Studio 시작하기]@ 버튼을 누르면 Azure Machine Learning Studio로 진입하게 된다.
 |
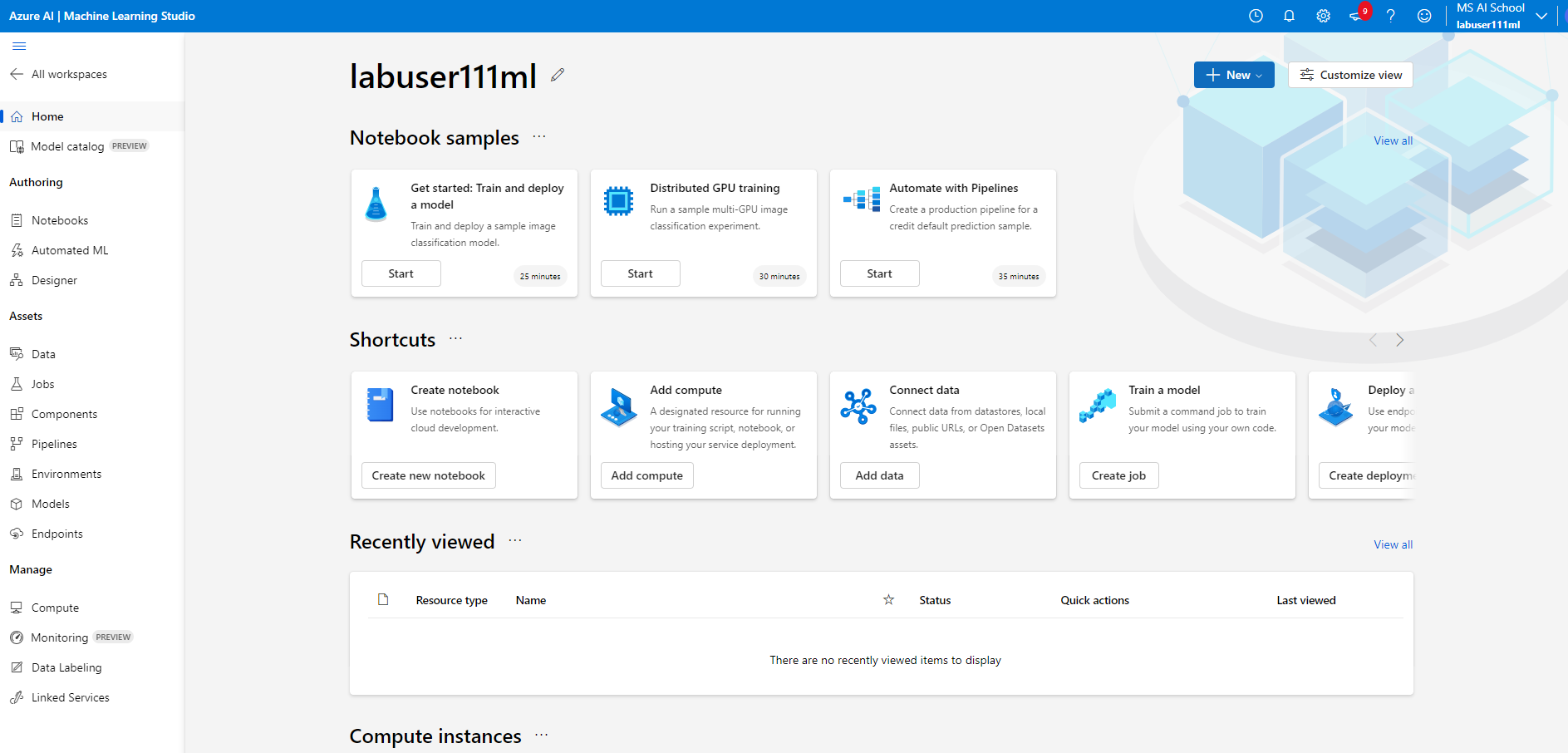 |
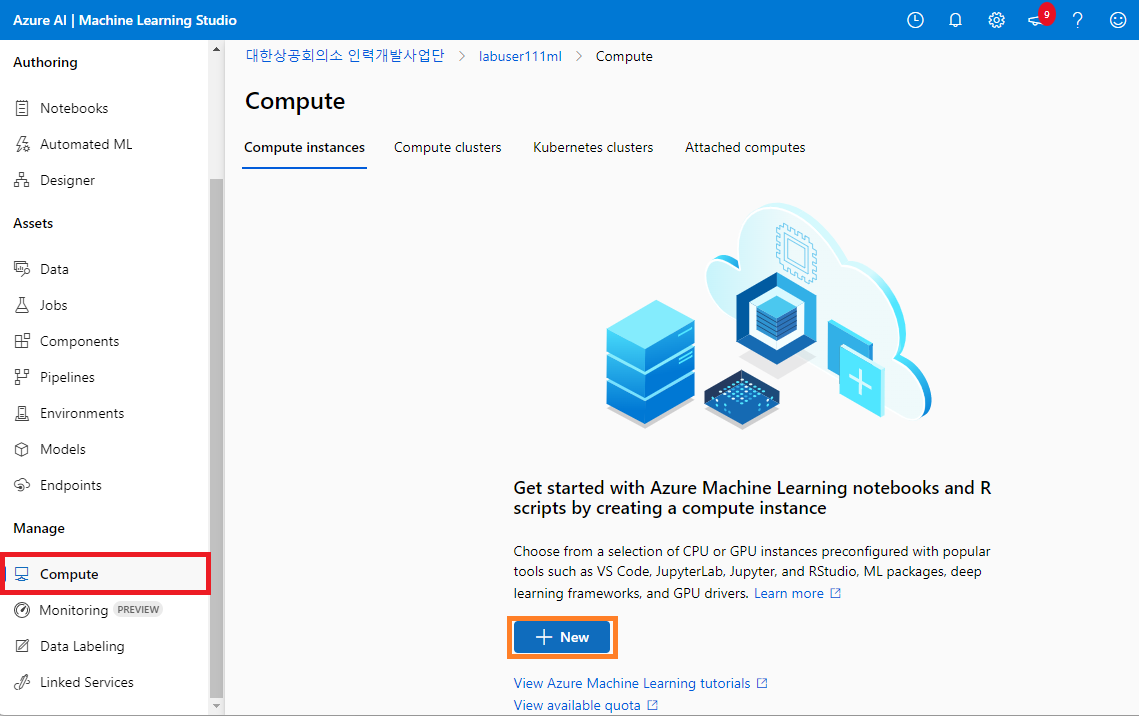
- @[Compute]@ 탭을 클릭한 후, @[New]@ 버튼을 클릭한다.
 |
 |
 |
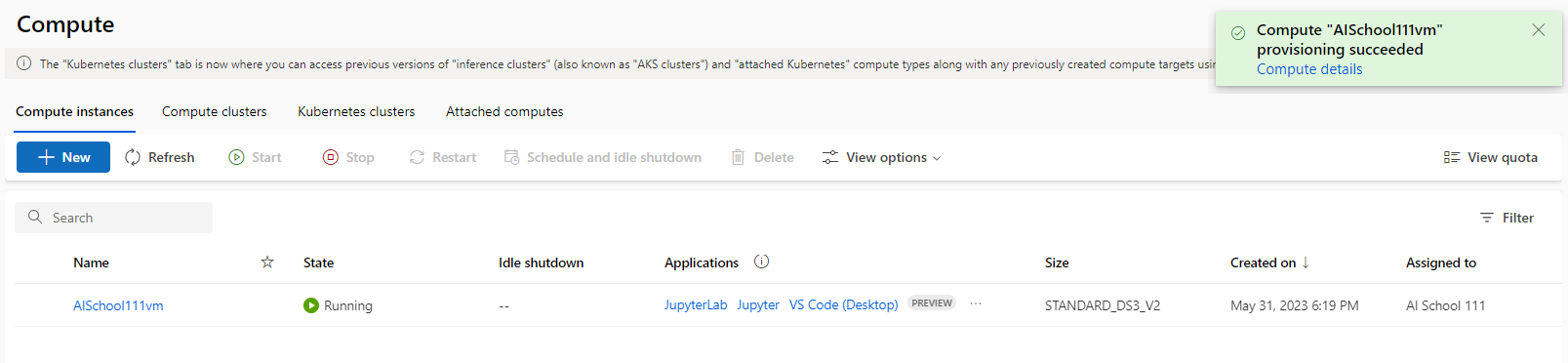 |
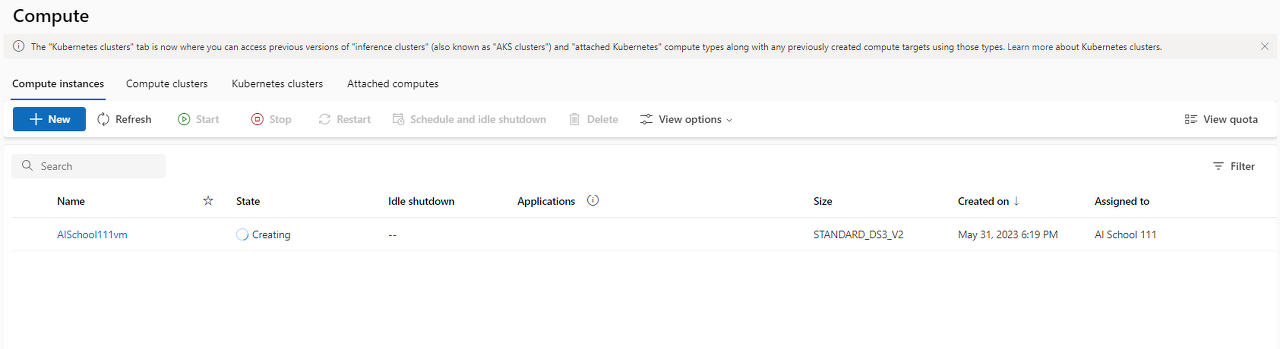
- 가상 머신이 생성되면, 왼쪽의 @[Designer]@ 탭을 클릭한 후, @[Create a new pipeline using classing prebuilt components]@를 클릭한다.
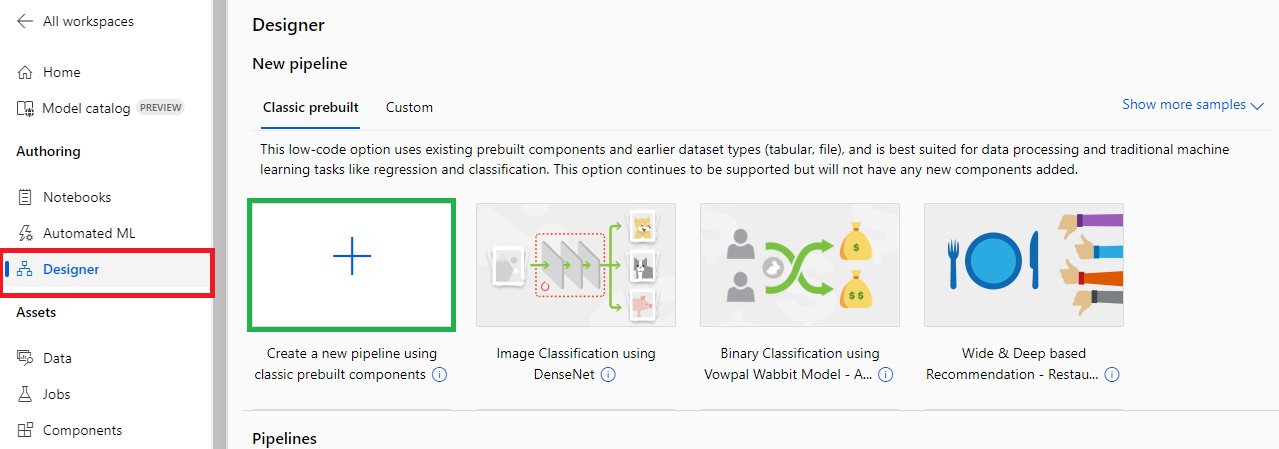
- 여러가지 컴포넌트(Component)들을 볼 수 있다. Orange 프로그램처럼 여러가지 컴포넌트들을 끌어다 사용할 수 있다.
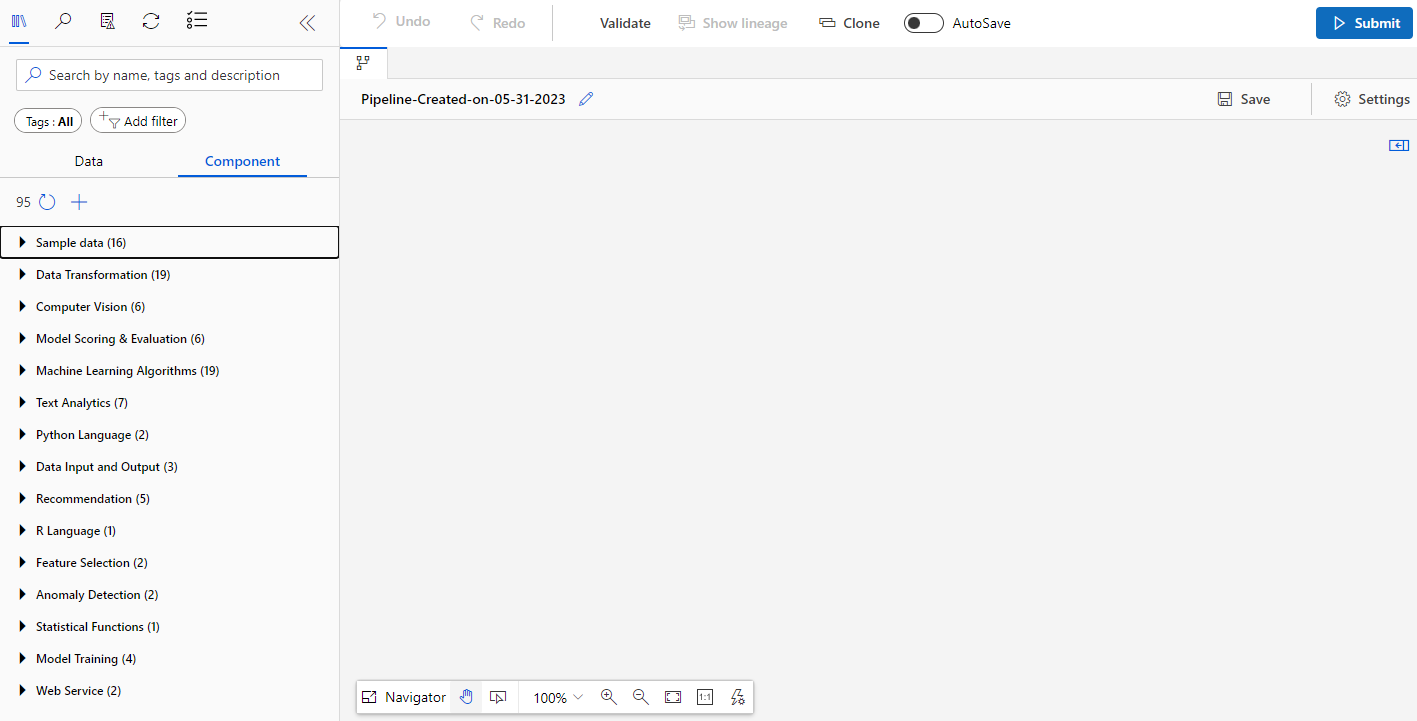
간단한 모델 만들어보기
- Designer를 이용하여 근속 연수에 따라 연봉을 예측해주는 간단한 모델을 만들어보자.
- @[Data Input and Output]@ 섹션에서 @[Enter Data Manually]@ 컴포넌트를 끌어다 놓고, 해당 컴포넌트를 더블 클릭해준다. 그리고 @[Data]@를 아래의 사진처럼 입력해준다.

- 좌측 상단의 @[Submit]@ 버튼을 클릭한다. 아직 가상 머신을 등록하지 않았기 때문에 오류 메시지가 출력된다.
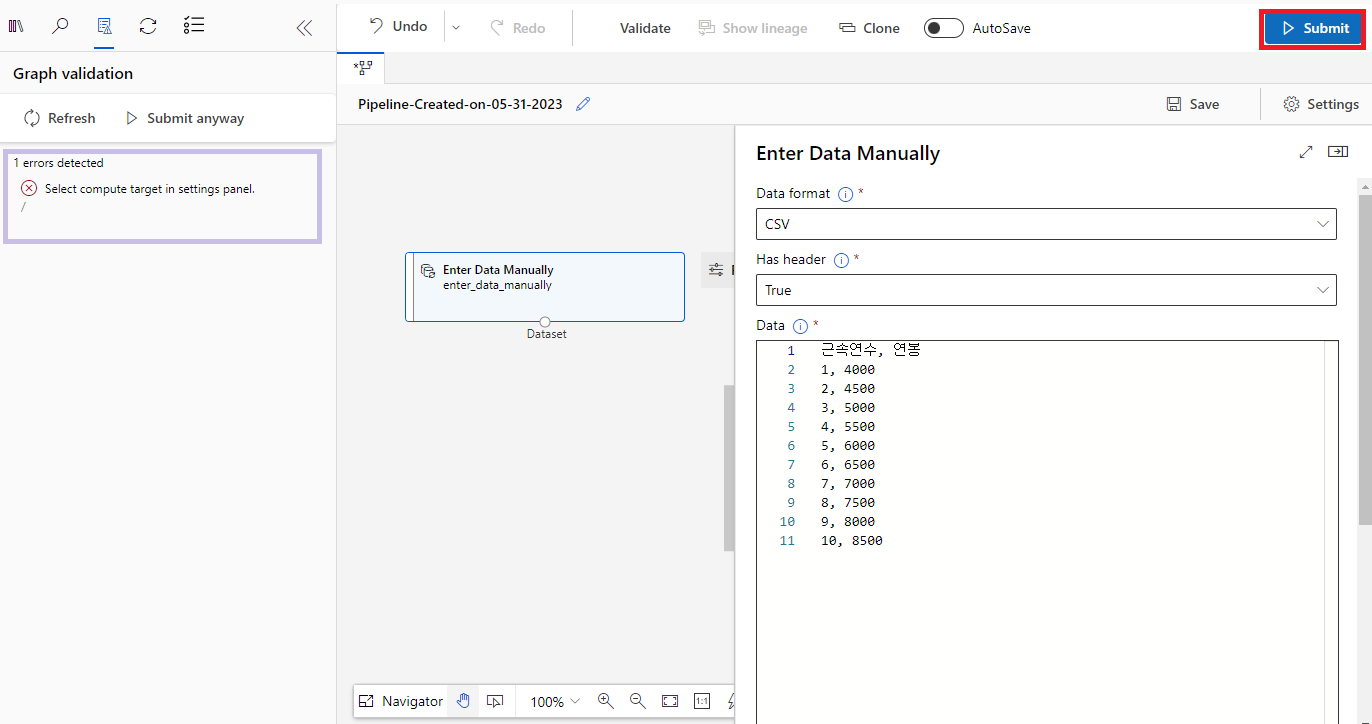
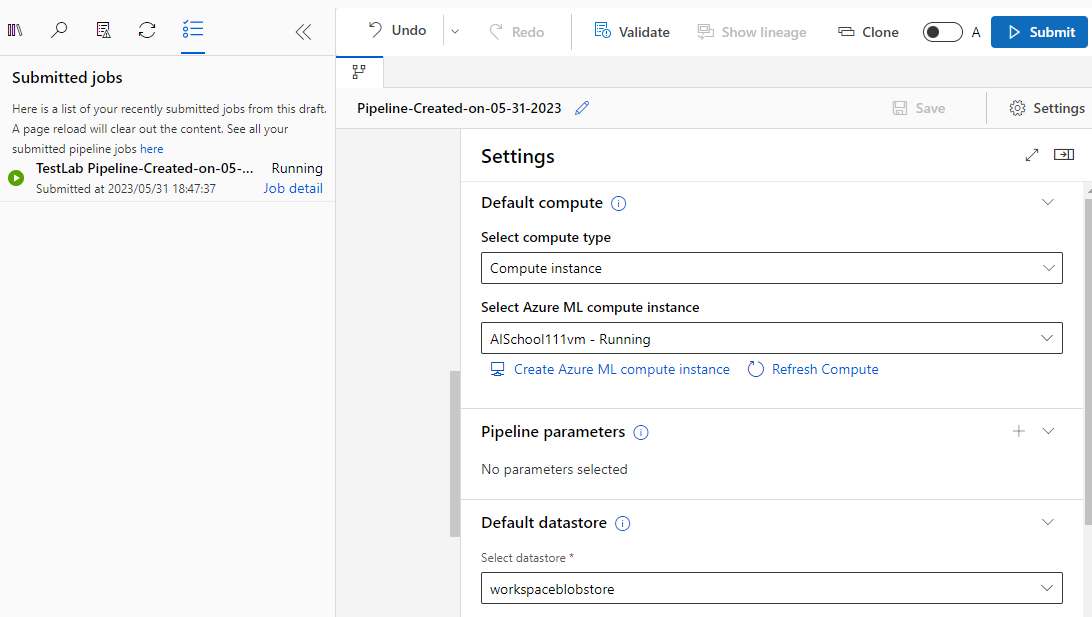
- 좌측 상단에서 @[Settings]@ 버튼을 클릭한 후, Compute Type을 @Compute Instance@로 설정한다. 그리고 Compute Instance를 생성했던 처음에 생성했던 가상 머신을 설정해준다. 그리고 상단의 @[Submit]@ 버튼을 클릭한다.

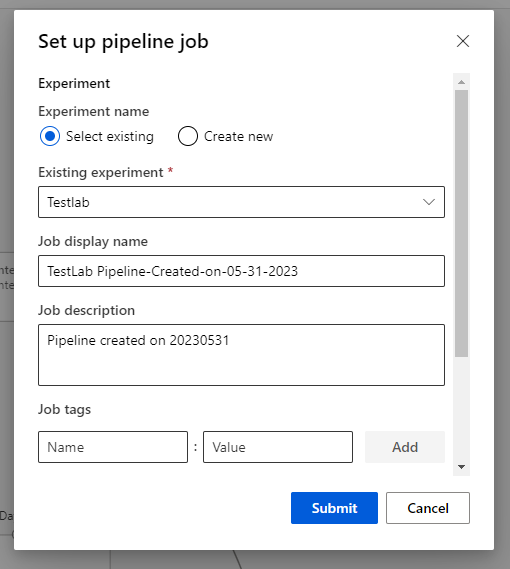
- @[Experiment name]@을 @Create new@로 설정한 후 @[Submit]@ 버튼을 클릭한다. 왼쪽에 성공적으로 Submitted 되었다는 메시지를 확인할 수 있다. 그리고 메시지의 @[Job detail]@ 링크를 클릭한다.
 |
 |
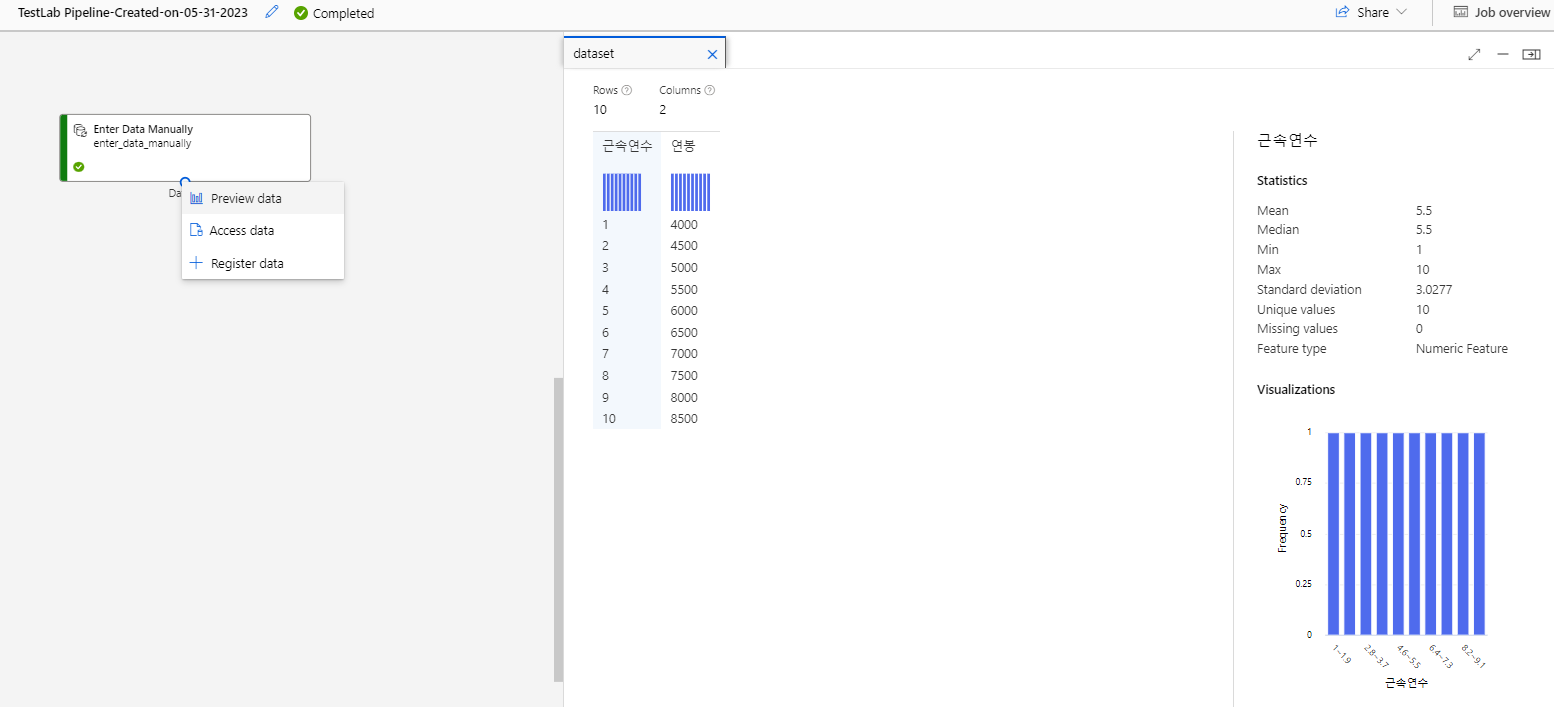
- 다음과 같이 모듈의 @o@ 아이콘을 클릭한 후 마우스 오른쪽 버튼을 클릭한 후. @[Preview data]@ 항목을 클릭하면 데이터에 대한 분석 정보를 확인할 수 있다.
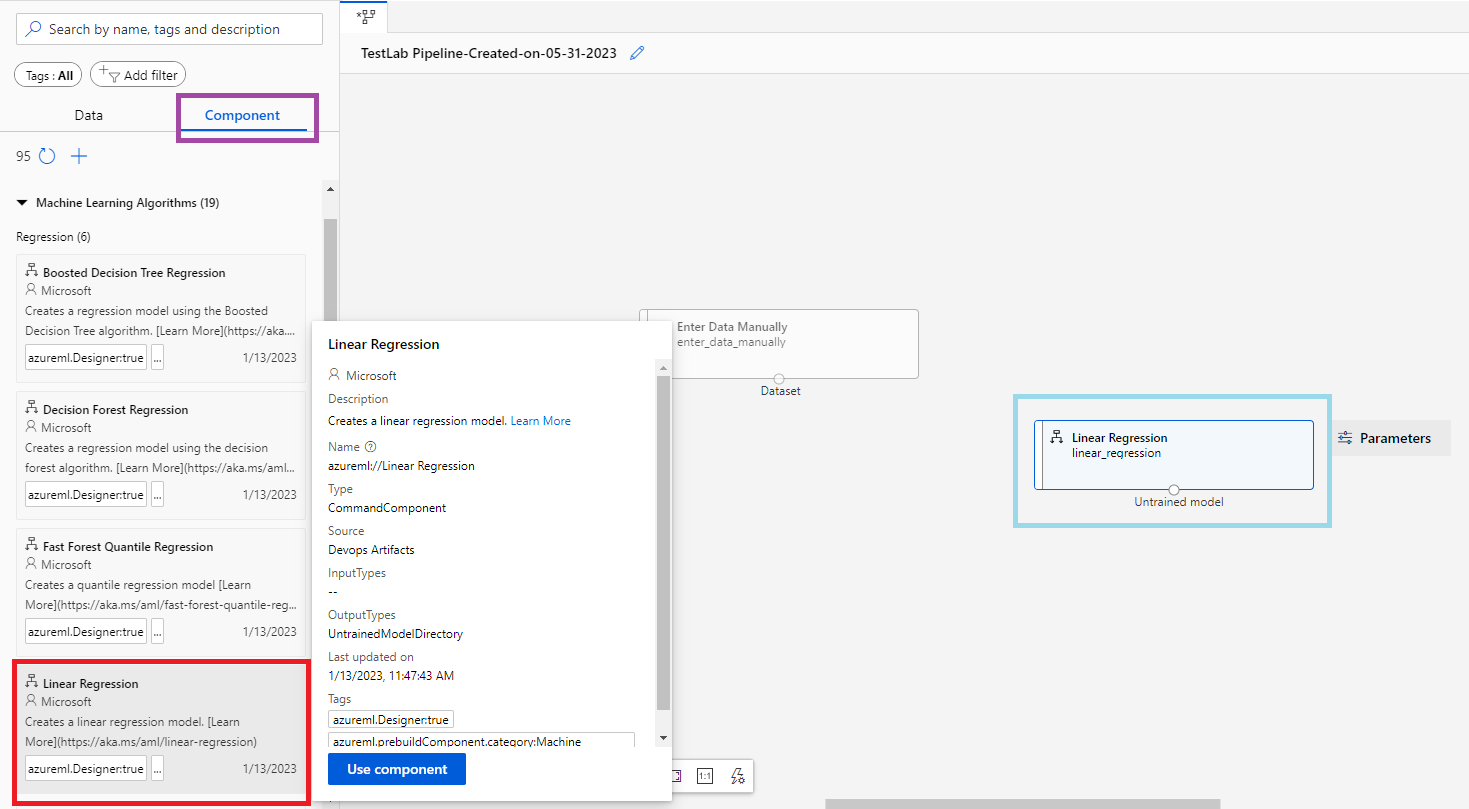
- @[Component]@ 탭 > @[Machine Learning Algorithms]@ 섹션에서 @[Linear Regression]@ 컴포넌트를 끌어온다.
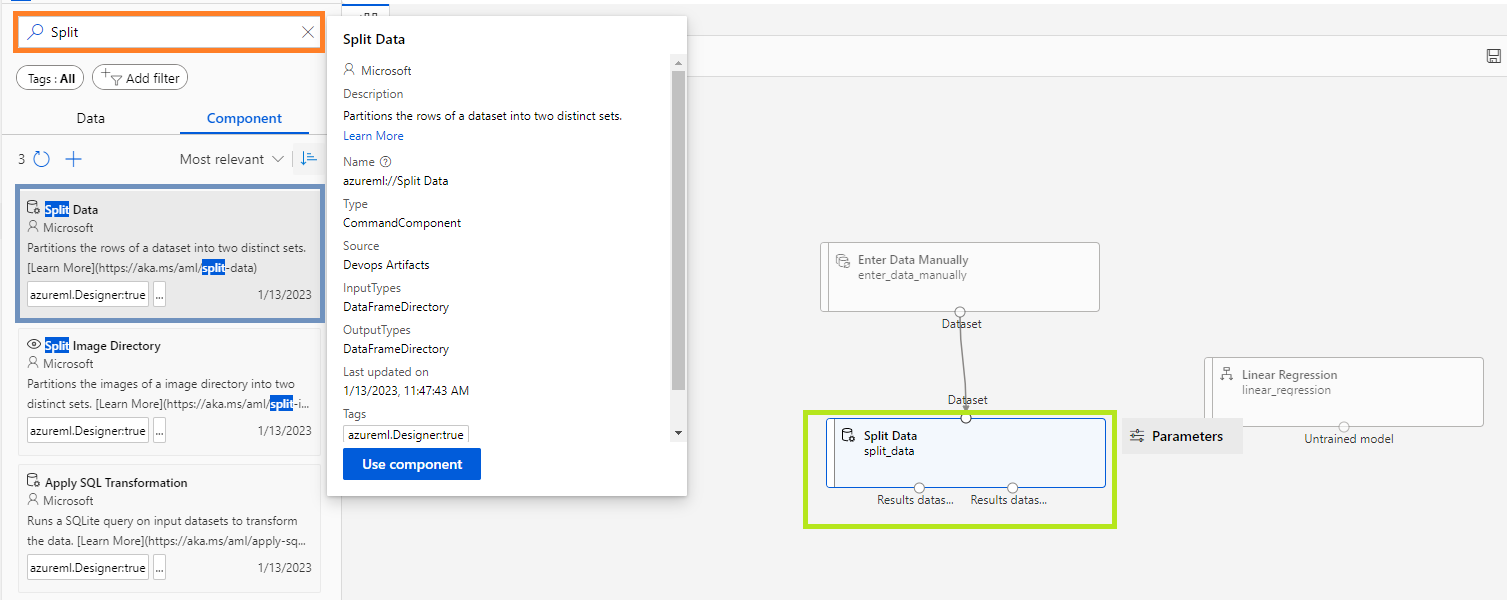
- 그리고 컴포넌트 검색창에 @[Split]@을 검색하여 @[Split Data]@ 컴포넌트를 끌어온다. 그리고 @[Enter Data Manually]@ 컴포넌트의 데이터셋(Dataset)을 @[Split Data]@ 컴포넌트의 상단에 연결해준다. @[Split Data]@ 컴포넌트의 왼쪽 Output은 학습용 데이터로 사용하고, 오른쪽 Output은 테스트용 데이터로 사용하게끔 하면 된다.
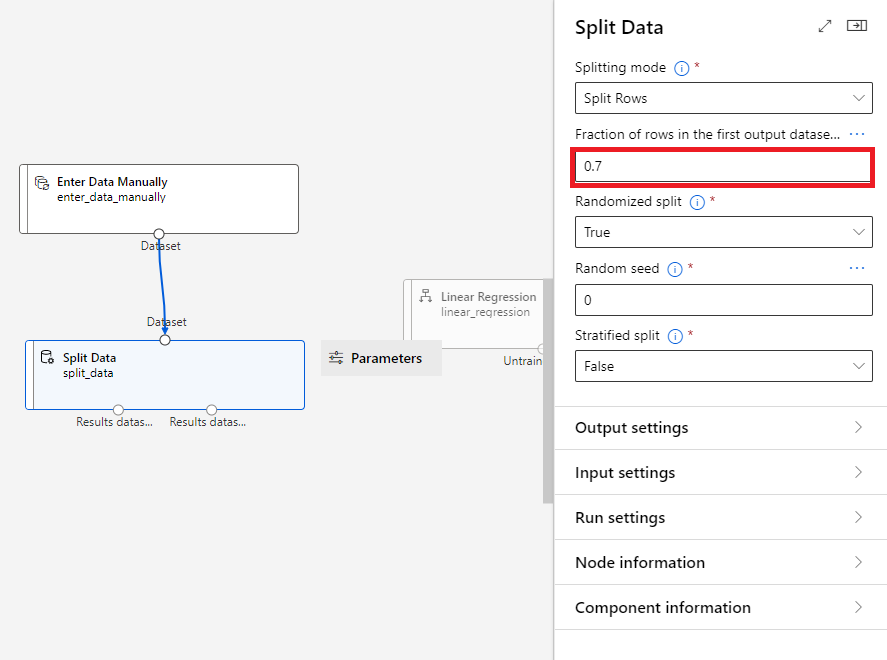
- @[Split Data]@ 컴포넌트를 더블 클릭한 후, 다음과 같이 @[Fraction of rows in the output database...]@를 @0.7@로 설정해준다.
- 컴포넌트 검색창에 @[Train]@을 검색한 후, @[Train Model]@ 컴포넌트를 끌어온다. 그리고 아래 그림처럼 @[Split Data]@ 컴포넌트와 @[Linear Regression]@ 컴포넌트를 @[Train Model]@ 컴포넌트에 연결해준다.
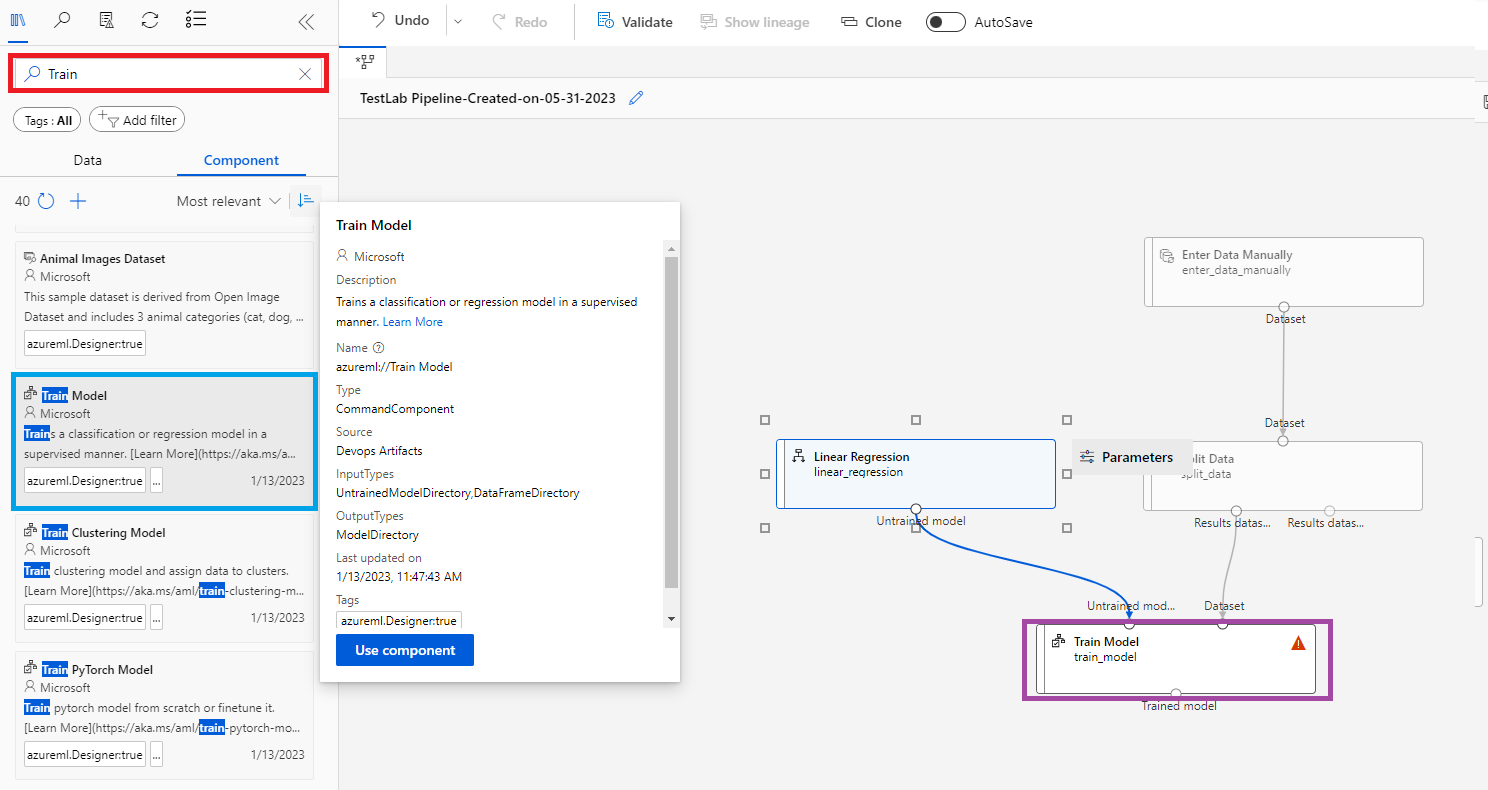
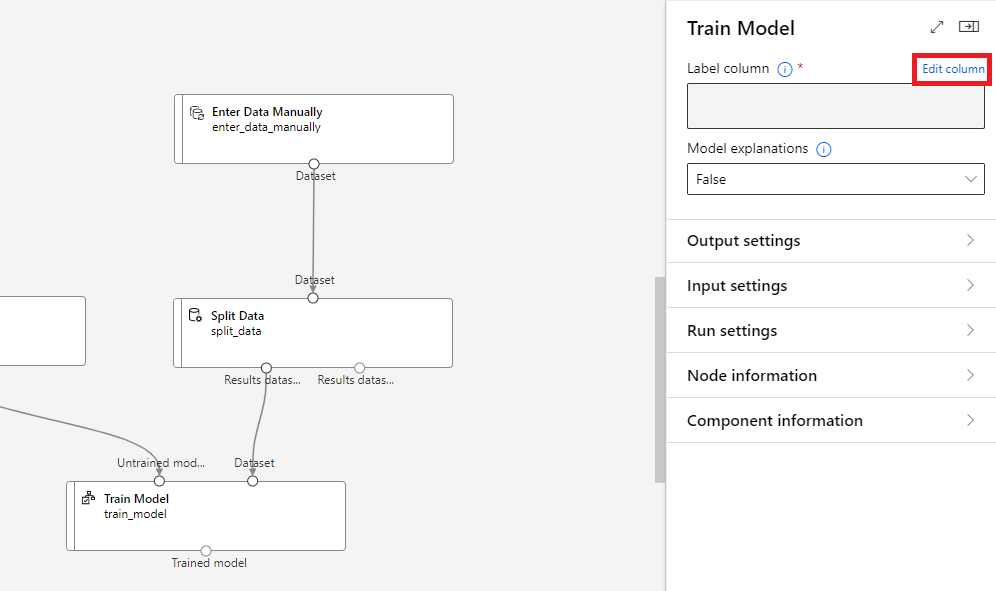
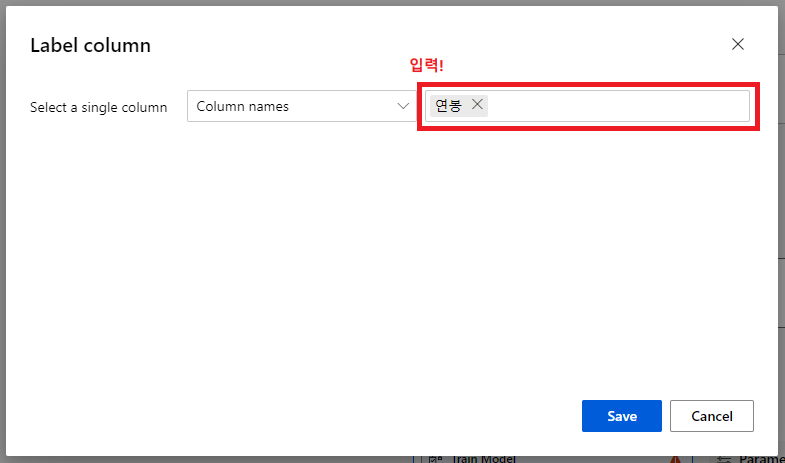
- @[Train Model]@ 컴포넌트에 경고 표시가 되어있다. 레이블 컬럼(Label Column)이 설정되지 않았기 때문이다. 이 문제를 해결하기 위해 @[Train Model]@ 컴포넌트를 더블 클릭한 후, @Label Column@을 @연봉@으로 설정해준다.
 |
 |
- 컴포넌트 검색창에 @[Score]@을 검색한 후, @[Score Model]@ 컴포넌트를 끌어온다. 그리고 아래 그림처럼 @[Split Data]@ 컴포넌트와 @[Train Model]@ 컴포넌트를 @[Score Model]@ 컴포넌트에 연결해준다. (@[Split Data]@ 모델의 오른쪽 데이터셋(테스트 데이터셋)을 @[Score Model]@ 컴포넌트의 입력으로 주어, @[Split Data]@ 모델의 왼쪽 데이터셋(훈련용 데이터셋)을 Linear Regression으로 훈련한 모델을 검증해보는 작업이다.)

- 컴포넌트 검색창에 @[Evaluate]@을 검색한 후, @[Evaluate Model]@ 컴포넌트를 끌어온다. 그리고 아래 그림처럼 @[Score Model]@ 컴포넌트의 @Scored dataset@을 @[Evaluate Model]@ 컴포넌트에 연결해준다. 그리고 우측 상단의 @[Submit]@ 버튼을 클릭한다.

- @The port(s) Scored_dataset ... Recommender ...@ 에러 메시지가 출력되면 무시하고 @[Submit anyway]@ 버튼을 클릭해준다. 그리고 처음에 생성해주었던 job을 선택해준다. (@Select existing@) 학습이 완료되면, 성공했다는 알림에 있는 @[Job detail]@을 클릭한다.
 |
 |
- @[Split Data]@ 컴포넌트의 @o@ 아이콘에 마우스 커서를 올리고, 마우스 오른쪽 버튼을 눌러서 @[Preview data]@를 클릭해본다. 데이터가 초기에 설정햇던데로 7:3의 비율로 분할되어 있는 것을 확인할 수 있다.
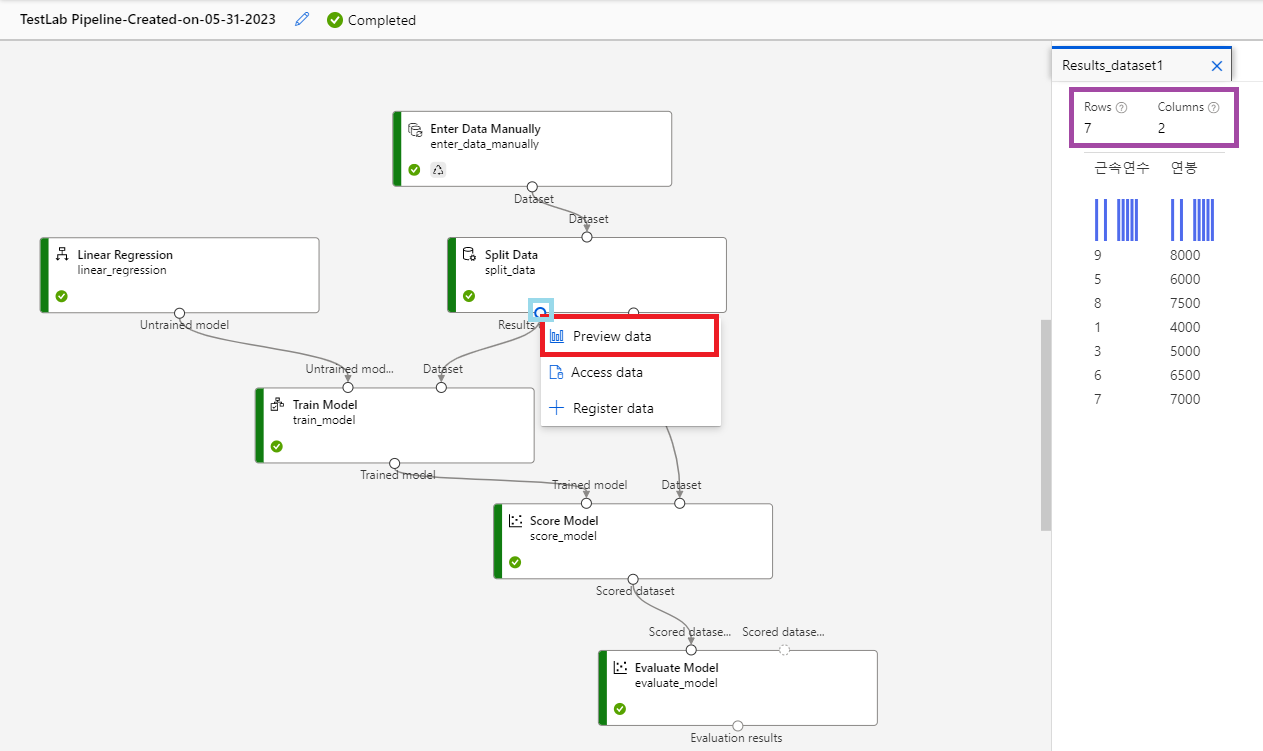
- 똑같이 @[Score Model]@ 컴포넌트의 @o@ 아이콘에 마우스 커서를 올리고, 마우스 오른쪽 버튼을 눌러서 @[Preview data]@를 클릭해본다. 모델이 예측한 정보를 확인할 수 있다.

- 똑같이 @[Evaluate Model]@ 컴포넌트의 @o@ 아이콘에 마우스 커서를 올리고, 마우스 오른쪽 버튼을 눌러서 @[Preview data]@를 클릭해본다.
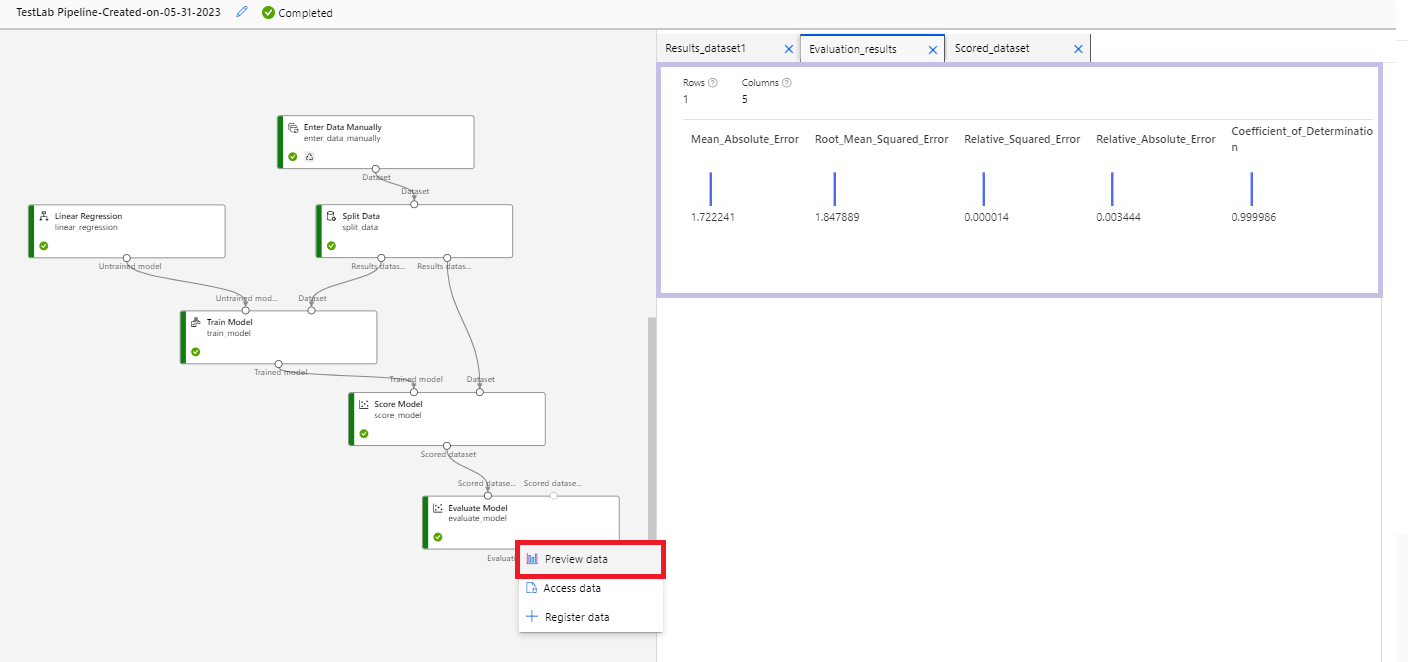
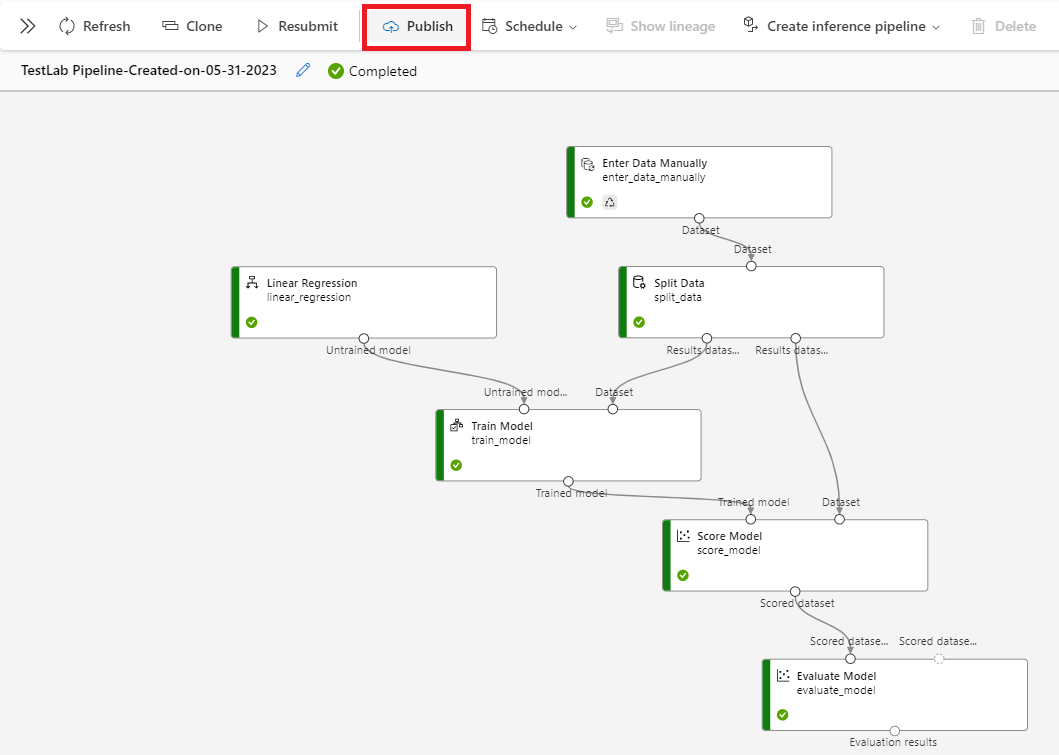
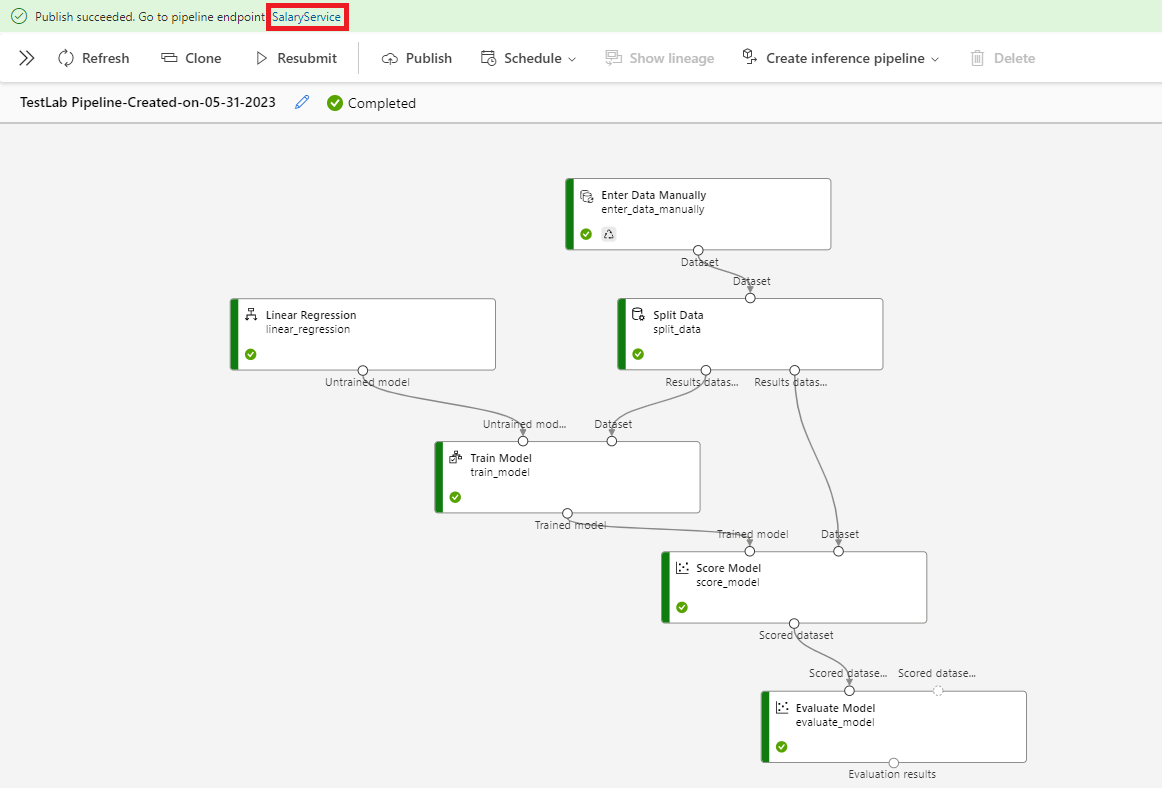
- 이로써 근속 연수에 따른 연봉 예측 모델이 만들어졌다. 이제 이 모델을 배포해보자. 상단의 @[Publish]@ 버튼을 클릭한 후, @[PipelineEndpoint@ 옵션을 @[Create new]@로 설정한 후, @PipelineEndpoint@ 이름을 지정해준다. 그리고 @[Publish]@ 버튼을 클릭한다. 배포가 완료되면 상단의 알림창에서 본인이 지정한 PipelineEndpoint 이름(@SalaryService@)의 링크를 클릭한다. 그러면 접속에 필요한 엔드포인트(Endpoint)를 확인할 수 있다.
 |
 |
 |
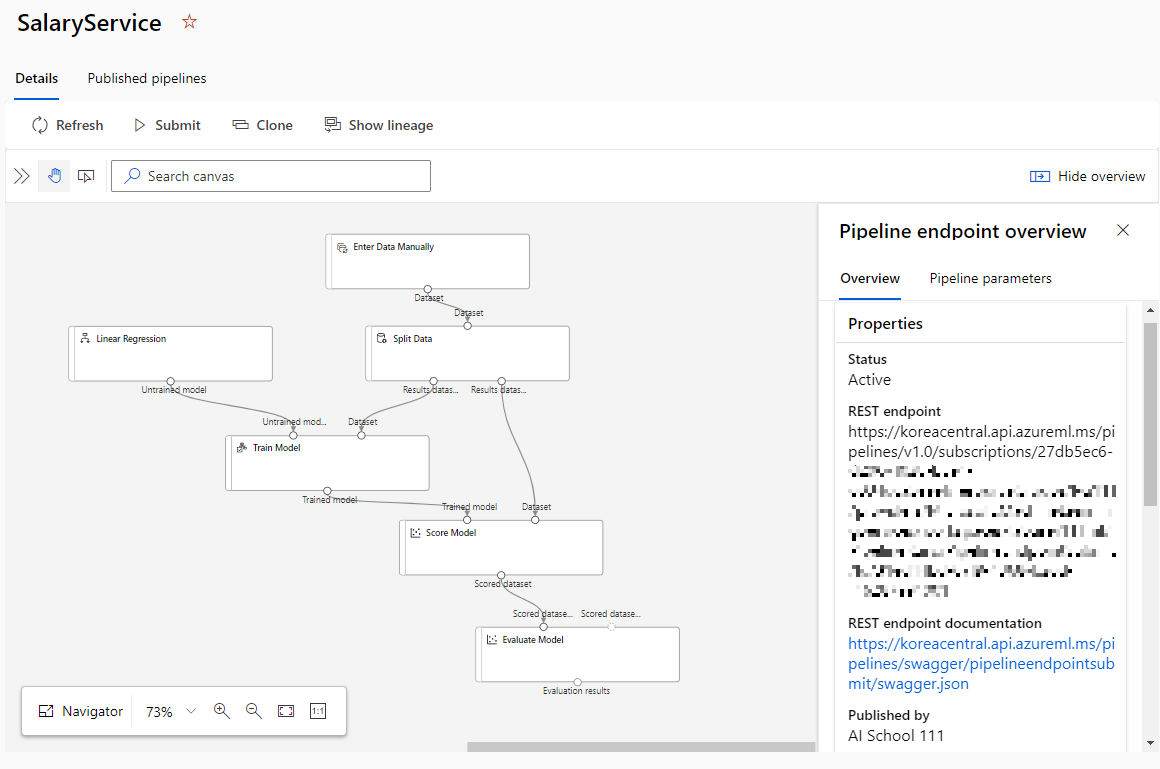 |
- ChatGPT에게 '이 엔드포인트(@REST endpoint documentation@)를 활용하여 파이썬 코드를 만들어줘.'와 같이 요구하여 코드를 간편하게 얻을 수 있다.
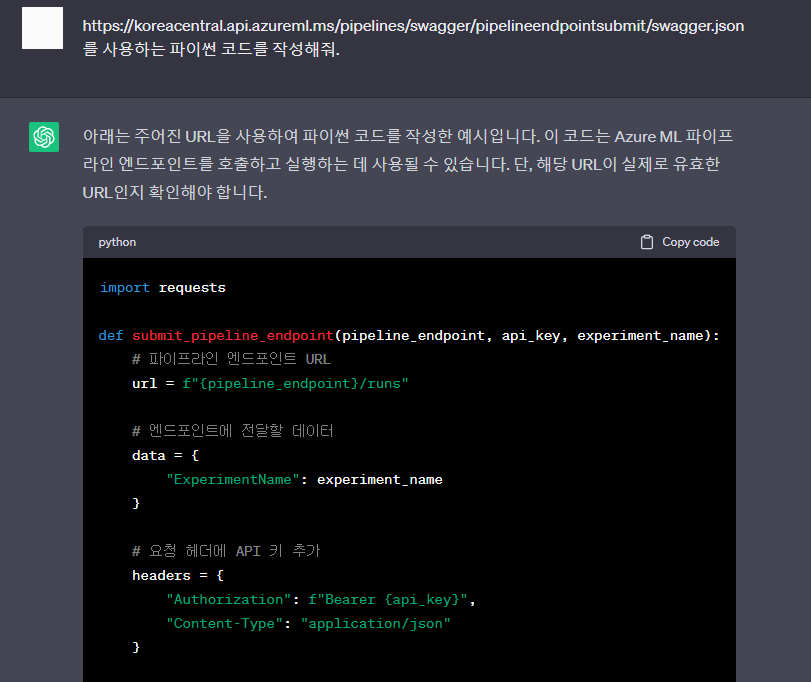
import requests
def submit_pipeline_endpoint(pipeline_endpoint, api_key, experiment_name):
# 파이프라인 엔드포인트 URL
url = f"{pipeline_endpoint}/runs"
# 엔드포인트에 전달할 데이터
data = {
"ExperimentName": experiment_name
}
# 요청 헤더에 API 키 추가
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
try:
# POST 요청 보내기
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
# 응답 확인
response_json = response.json()
run_id = response_json.get("runId")
if run_id:
print(f"파이프라인 실행이 성공적으로 제출되었습니다. (Run ID: {run_id})")
else:
print("파이프라인 실행 제출에 실패했습니다.")
except requests.exceptions.RequestException as e:
print(f"파이프라인 실행 제출 중 오류가 발생했습니다: {e}")
# 파이프라인 엔드포인트 정보
pipeline_endpoint = "https://koreacentral.api.azureml.ms/pipelines/swagger/pipelineendpointsubmit"
api_key = "YOUR_API_KEY"
experiment_name = "YOUR_EXPERIMENT_NAME"
# 파이프라인 엔드포인트 호출 및 실행 제출
submit_pipeline_endpoint(pipeline_endpoint, api_key, experiment_name)
Azure Machine Learning Designer는 실무에서 거의 사용되지 않으니 참고만 한다.
- 다시 @Designer@로 돌아간다.

728x90
'Cloud > Azure' 카테고리의 다른 글
| [Azure] Visual Studio 서비스를 이용하여 CRUD 애플리케이션 제작하기 (0) | 2023.06.07 |
|---|---|
| [Azure] Azure Machine Learning Service 사용해보기 : Notebooks (0) | 2023.06.01 |
| [Azure] Azure Machine Learning Service 사용해보기 : Automated ML (0) | 2023.05.31 |
| [Azure] 쿠버네티스(Kubernetes) 실습하기 : AKS(Azure Kubernetes Service) 실습 (0) | 2023.05.30 |
| [Azure] 쿠버네티스(Kubernetes) 실습하기 : 간단한 실습 해보기 (0) | 2023.05.29 |
| [Azure] 쿠버네티스(Kubernetes) 실습하기 : 미니쿠베(minikube) 설치하기 (0) | 2023.05.27 |
| [Azure] 도커(Docker) 실습하기 : 도커 이미지를 다른 사람과 공유하여 사용해보기 (0) | 2023.05.27 |
| [Azure] 도커(Docker) 실습하기 : Dockerfile을 이용하여 직접 도커 이미지를 만들고 컨테이너 만들어보기 (0) | 2023.05.27 |