해설 : 순수 관계 연산자로는 셀프조디(SELECT, PROJECT, JOIN, DIVIDE)가 있다.
문제 2
Q. 다음 중 아래 데이터 모델을 참고하여 설명에 맞게 올바르게 작성한 SQL 문장을 2개 고르시오.
[설명] 우리는 매일 배치작업을 통하여 고객에게 추천할 컨텐츠를 생성하고 고객에게 추천 서비스를 제공한다. 추천 컨텐츠 엔티티에서 언제 추천을 해야 하는지를 정의하는 추천 대상일자가 있어 해당일자에만 컨텐츠를 추천해야 한다. 또한 고객이 컨텐츠를 추천 받았을 때 선호하는 커텐츠가 아닌 경우에는 고객이 비선호 컨텐츠로 분류하여 더 이상 추천 받기를 원하지 않는다. 그러므로 우리는 비선호 컨텐츠 엔티티에 등록된 데이터에 대해서는 추천을 수행하지 않아야 한다.
※ 배치 작업이란? 어떤 처리를 연속적으로 하는 것이 아니고 일정량씩 나누어 처리하는 경우 그 일정량을 배치(Batch)라고 한다. 배치의 원뜻은 한 묶음이라는 의미이다. [기계공학용어사전] 예) 상품을 주문하는 로직은 그 당시에 발생하는 트랜잭션에 대한 처리이므로 배치작업이라 표현하지는 않는다. 하지만 상품별 주문량을 집계하는 로직의 경우 특정 조건(기간 등)으로 일괄처리를 해야함으로 배치작업이라 표현할 수 있다.
①
SELECT C.컨텐츠ID, C.컨텐츠명
FROM 고객 A INNER JOIN 추천컨텐츠 B
ON (A.고객ID = B.고객ID) INNER JOIN 컨텐츠 C
ON (B.컨텐츠ID = C.컨텐츠ID)
WHERE A.고객 = #custId#
AND B.추천대상일자 = TO_CHAR(SYSDATE, 'YYYY.MM.DD')
AND NOT EXISTS(SELECT X.컨텐츠ID
FROM 비선호컨텐츠 X
WHERE X.고객ID = B.고객ID);
②
SELECT C.컨텐츠ID, C.컨텐츠명
FROM 고객 A INNER JOIN 추천컨텐츠 B
ON (A.고객ID = #custId# AND A.고객ID = B.고객ID) INNER JOIN 컨텐츠 C
ON (B.컨텐츠ID = C.컨텐츠ID) RIGHT OUTER JOIN 비선호컨텐츠 D
ON (B.고객ID = D.고객ID AND B.컨텐츠ID = D.컨텐츠ID)
WHERE B.추천대상일자 = TO_CHAR(SYSDATE, 'YYYY.MM.DD')
AND B.컨텐츠ID IS NOT NULL;
③
SELECT C.컨텐츠ID, C.컨텐츠명
FROM 고객 A INNER JOIN 추천컨텐츠 B
ON (A.고객ID = B.고객ID) INNER JOIN 컨텐츠 C
ON (B.컨텐츠ID = C.컨텐츠ID) LEFT OUTER JOIN 비선호컨텐츠 D
ON (B.고객ID = D.고객ID AND B.컨텐츠ID = D.컨텐츠ID)
WHERE A.고객ID = #custId#
AND B.추천대상일자 = TO_CHAR(SYSDATE, 'YYYY.MM.DD')
AND D.컨텐츠ID IS NULL;
④
SELECT C.컨텐츠ID, C.컨텐츠명
FROM 고객 A INNER JOIN 추천컨텐츠 B
ON (A.고객ID = #custId# AND A.고객ID = B.고객ID) INNER JOIN 컨텐츠 C
ON (B.컨텐츠ID = C.컨텐츠ID)
WHERE B.추천대상일자 = TO_CHAR(SYSDATE, 'YYYY.MM.DD')
AND NOT EXISTS (SELECT X.컨텐츠ID
FROM 비선호컨텐츠 X
WHERE X.고객ID = B.고객ID
AND X.컨텐츠ID = B.컨텐츠ID);
정답 : ③, ④
해설 :
① NOT EXIST 절의 연관 서브쿼리에 X.컨텐츠ID = B.컨텐츠ID가 존재하지 않아 단 하나의 컨텐츠라도 비선호로 등록한 고객에 대해서는 모든 컨텐츠가 추천에서 배제된다. ② 추천컨텐츠를 기준으로 비선호컨텐츠와의 LEFT OUTER JOIN이 수행되고, 비선호컨텐츠의 컨텐츠ID에 대해서 IS NULL 조건(③번과 같이)이 있다면 정확히 비선호컨텐츠만 필터링할 수 있다. (고객이 비선호로 등록하지 않은 컨텐츠는 추천컨텐츠에만 등록 되어 있으므로)
문제 3
Q. 아래는 어느 회사의 생산 설비를 위한 데이터 모델의 일부에 대한 설명으로 가장 적절한 것을 2개 고르시오.
① 제품, 생산제품, 생산라인 엔티티를 Inner Join 하기 위해서 생산제품 엔티티는 WHERE 절에 최소 2번이 나타나야 한다. ② 제품과 생산라인 엔티티를 Join 시 적절한 Join 조건이 없으므로 가티시안 곱(Cartesian Product)이 발생한다. ③ 제품과 생산라인 엔티티에는 생산제품과 대응되지 않는 레코드는 없다. ④ 특정 생산라인번호에서 생산되는 제품의 제품명을 알기 위해서는 제품, 생산제품, 생산라인까지 3개 엔티티의 Inner Join이 필요하다.
정답 : ①, ②
해설 :
③ 데이터 모델을 보면 제품과 생산라인 엔티티에는 생산제품과 대응하지 않는 레코드가 있을 수 있다. ④ 특정 생산라인에서 생산되는 제품의 제품명을 알기 위해서는 제품과 생산제품까지 2개의 엔티티만을 Inner Join 하면 된다.
문제 4
Q. 아래의 테이블 스키마 정보를 참고하여, 다음 중 '구매 이력이 있는 고객 중 구매 횟수가 3회 이상인 고객의 이름과 등급을 출력하시오.' 라는 질의에 대해 아래 SQL 문장의 ( ㄱ ), ( ㄴ ) 에 들어 갈 구문으로 가장 적절한 것은?
SELECT A.이름, A.등급
FROM 고객 A
( ㄱ )
GROUP BY A.이름, A.등급
( ㄴ )
① (ㄱ) : INNER JOIN 구매정보B ON A.고객번호= B.고객번호 (ㄴ) : HAVING SUM(B.구매번호)>= 3 ② (ㄱ) : INNER JOIN 구매정보B ON A.고객번호= B.고객번호 (ㄴ) : HAVING COUNT(B.구매번호)>= 3 ③ (ㄱ) : LEFT OUTER JOIN 구매정보 B ON A.고객번호 = B.고객번호 (ㄴ) : HAVING SUM(B.구매번호) >= 3 ④ (ㄱ) : INNER JOIN 구매정보 B ON A.고객번호 = B.고객번호 (ㄴ) : WHERE B. 구매번호 〉= 3
정답 : ②
해설 : 구매 이력이 있어야 하므로 INNER JOIN이 필요하며, 구매 횟수이므로 COUNT 함수를 사용한다.
문제 5
Q. 아래는 어느 회사의 정산 데이터 모델의 일부이며 고객이 서비스를 사용한 시간대에 따라 차등 단가를 적용하려고 한다. 다음 중 시간대별사용량 테이블을 기반으로 고객별 사용금액을 추출하는 SQL으로 가장 적절한 것은?
①
SELECT A.고객ID, A.고객명, SUM(B.사용량 * C.단가 AS 사용금액
FROM 고객 A INNER JOIN 시간대별사용량 B
ON (A.고객ID = B.고객ID) INNER JOIN 시간대구간 C
ON (B.사용시간대 <= C.시작시간대 AND B.사용시간대 >= C.종료시간대)
GROUP BY A.고객ID, A.고객명
ORDER BY A.고객ID, A.고객명;
②
SELECT A.고객ID, A.고객명, SUM(B.사용량 * C.단가) AS 사용금액
FROM 고객 A INNER JOIN 시간대별사용량 B INNER JOIN 시간대구간 C
ON (A.고객ID = B.고객ID AND B.사용시간대
BETWEEN C.시작시간대 AND C.종료시간대)
GROUP BY A.고객ID, A.고객명
ORDER BY A.고객ID, A.고객명;
③
SELECT A.고객ID, A.고객명, SUM(B.사용량 * C.단가) AS 사용금액
FROM 고객 A INNER JOIN 시간대별사용량 B
ON (A.고객ID = B.고객ID) INNER JOIN 시간대구간 C
ON B.사용시간대 BETWEEN C.시작시간대 AND C.종료시간대
GROUP BY A.고객ID, A.고객명
ORDER BY A.고객ID, A.고객명;
④
SELECT A.고객ID, A.고객명, SUM(B.사용량 * C.단가) AS 사용금액
FROM 고객 A INNER JOIN 시간대별사용량 B
ON (A.고객ID = B.고객ID) BETWEEN JOIN 시간대구간 C
GROUP BY A.고객ID, A.고객명
ORDER BY A.고객ID, A.고객명;
정답 : ③
해설 :
① 두 번째 ON 절이 B.사용시간대 BETWEEN C.시작시간대 AND C.시작시간대 가 되어야 한다. ② INNER JOIN 구문 오류가 발생한다. ④ BETWEEN JOIN 이란 구문은 없다. 구문 오류가 발생한다.
문제 6
Q. 다음 중 팀(TEAM) 테이블과 구장(STADIUM) 테이블의 관계를 이용해서 소속팀이 가지고 있는 전용구장의 정보를 팀의 정보와 함께 출력하는 SQL을 작성할 때 결과가 다른 것은?
①
SELECT T.REGION_NAME, T.TEAM_NAME, T.STADIUM_ID,
S.STADIUM_NAME
FROM TEAM T INNER JOIN STADIUM S
USING (T.STADIUM_ID = S.STADIUM_ID);
②
SELECT TEAM.REGION_NAME, TEAM.TEAM_NAME, TEAM.STADIUM_ID,
STADIUM.STADIUM_NAME
FROM TEAM INNER JOIN STADIUM
ON (TEAM.STADIUM_ID = STADIUM.STADIUM_ID);
③
SELECT T.REGION_NAME, T.TEAM_NAME, T.STADIUM_ID,
S.STADIUM_NAME
FROM TEAM T, STADIUM S
WHERE T.STADIUM_ID = S.STADIUM_ID;
④
SELECT TEAM.REGION_NAME, TEAM.TEAM_NAME,
TEAM.STADIUM_ID, STADIUM.STADIUM_NAME
FROM TEAM, STADIUM
WHERE TEAM.STADIUM_ID = STADIUM.STADIUM_ID;
정답 : ① 해설 : USING 조건절을 이용한 EQUI JOIN 에서도 NATURAL JOIN과 마찬가지로 JOIN 칼럼에 대해서는 ALIAS나 테이블 이름과 같은 접두사를 붙일 수 없다. 따라서 SYNTAX 에러가 발생한다. ▶ USING (STADIUM_ID) (O) ▶ SELECT T.REGION_NAME, T.TEAM_NAME, STADIUM_ID, S.STADIUM_NAME (O)
문제 7
Q. 아래의 사례1은 Cartesian Product를 만들기 위한 SQL 문장이며 사례1과 같은 결과를 얻기 위해 사례2 SQL 문장의 ( ㄱ ) 안에 들어갈 내용을 작성하시오.
[사례1]
SELECT ENAME, DNAME
FROM EMP, DEPT
ORDER BY ENAME;
[사례2]
SELECT ENAME, DNAME
FROM EMP ( ㄱ ) DEPT
ORDER BY ENAME;
정답 : CROSS JOIN 해설 : CROSS JOIN은 일반 집합 연산자의 PRODUCT의 개념으로 테이블 간 JOIN 조건이 없는 경우 생길 수 있는 모든 데이터의 조합을 의미한다. 조건절이 없거나CROSS JOIN 키워드를 사용할 수 있다.
문제 8
Q. 다음 중 아래 테이블들을 대상으로 SQL 문장을 수행한 결과로 가장 적절한 것은?
[SQL]
SELECT A.고객번호, A.고객명, B.단말기ID, B.단말기명, C.OSID, C.OS명
FROM 고객 A LEFT OUTER JOIN 단말기 B
ON (A.고객번호 IN (11000, 12000) AND A.단말기ID = B.단말기 ID) LEFT OUTER JOIN OS C
ON (B.OSID = C.OSID)
ORDER BY A.고객번호;
①
②
③
④
정답 : ① 해설 : WHERE 절에 A.고객번호 IN (11000, 12000) 조건을 넣었다면 정답은 ②번이 되었을 것이나, ON 절에 A.고객번호 IN (11000, 12000) 조건을 넣었기 때문에 모든 고객에 대해서 출력을 하되, JOIN 대상 데이터를 고객번호 11000과 12000으로 제한되어 ①번과 같은 결과가 출력된다.
문제 9
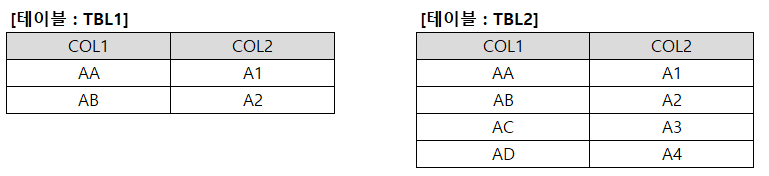
Q. 다음 중 아래 (1), (2), (3)의 SQL에서 실행 결과가 같은 것은?
(1)
SELECT A.ID, B.ID
FROM TBL1 A FULL OUTER JOIN TBL2 B
ON A.ID = B.ID;
(2)
SELECT A.ID, B.ID
FROM TBL1 A LEFT OUTER JOIN TBL2 B
ON A.ID = B.ID
UNION
SELECT A.ID, B.ID
FROM TBL1 A RIGHT OUTER JOIN TBL2 B
ON A.ID = B.ID;
(3)
SELECT A.ID, B.ID
FROM TBL1 A, TBL2 B
WHERE A.ID = B.ID
UNION ALL
SELECT A.ID, NULL
FROM TBL1 A
WHERE NOT EXISTS (SELECT 1 FROM TBL2 B WHERE A.ID = B.ID)
UNION ALL
SELECT NULL, B.ID
FROM TBL2 B
WHERE NOT EXISTS (SELECT 1 FROM TBL1 A WHERE B.ID = A.ID);
① 1, 2 ② 1, 3 ③ 2, 3 ④ 1, 2, 3
정답 : ④ 해설 : 보기의 3개의 SQL은 모두 FULL OUTER JOIN과 동일한 결과를 반환한다.
문제 10
Q. 아래의 EMP 테이블과 DEPT 테이블에서 밑줄 친 속성은 주키이며 EMP.C는 DEPT와 연결된 외래키이다. EMP 테이블과 DEPT 테이블을 LEFT, FULL, RIGHT 외부 조인(OUTER JOIN)하면 생성되는 결과 건수로 가장 적절한 것은?
① 3건, 5건, 4건 ② 4건, 5건, 3건 ③ 3건, 4건, 4건 ④ 3건, 4건, 5건
정답 : ① 해설 : 주키와 외래키는 영향을 미치지 않는다.
문제 11
Q. 신규 부서의 경우 일시적으로 사원이 없는 경우도 있다고 가정하고 DEPT와 EMP를 조인하되, 사원이 없는 부서 정보도 같이 출력하도록 할 때, 아래 SQL 문장의 ( ㄱ ) 안에 들어갈 내용을 기술하시오.
SELECT E.ENAME, D.DEPTNO, D.DNAME
FROM DEPT D ( ㄱ ) EMP E
ON D.DEPTNO = E.DEPTNO;
정답 : LEFT JOIN 또는 LEFT OUTER JOIN 해설 : LEFT OUTER JOIN은 좌측 테이블이 기준이 되어 결과를 생성한다. 즉, TABLE A와 B가 있을 때(TABLE 'A'가 기준이 됨.), A와 B를 비교해서 B의 JOIN 칼럼에서 같은 값이 있을 때 B 테이블에서 해당 데이터를 가져오고, B의 JOIN 칼럼에서 같은 값이 없는 경우에는 B 테이블에서 가져오는 칼럼들은 NULL 값으로 채운다. LEFT JOIN으로 OUTER 키워드를 생략해서 사용할 수 있다.
문제 12
Q. 다음 중 아래와 같은 데이터 상황에서 SQL의 수행 결과로 가장 적절한 것은?
SELECT *
FROM TAB1 A LEFT OUTER JOIN TAB2 B
ON (A.C1 = B.C1 AND B.C2 BETWEEN 1 AND 3);
①
②
③
④
정답 : ② 해설 : OUTER JOIN에서 ON 절은 조인할 대상을 결정한다. 그러나 기준 테이블은 항상 모두 표시된다. 결과 건에 대한 필터링은 WHERE 절에서 수행된다.
문제 13
Q. 아래와 같은 데이터 모델에서 ORACLE을 기준으로 SQL을 작성하였다. 그러나 SQL Server에서도 동일한 결과를 보장할 수 있도록 ANSI 구문으로 SQL을 변경하려고 한다. 다음 중 아래의 SQL을 ANSI 표준 구문으로 변경한 것으로 가장 적절한 것은?
[SQL]
SELECT A.게시판ID, A.게시판명, COUNT(B.게시글ID) AS CNT
FROM 게시판 A, 게시글 B
WHERE A.게시판ID = B.게시판ID(+)
AND B.삭제여부(+) = 'N'
AND A.사용여부 = 'Y'
GROUP BY A.게시판ID, A.게시판명
ORDER BY A.게시판ID;
①
SELECT A.게시판ID, A.게시판명, COUNT(B.게시글ID) AS CNT
FROM 게시판 A LEFT OUTER JOIN 게시글 B
ON (A.게시판ID = B.게시판ID AND B.삭제여부 = 'N')
WHERE A.사용여부 = Y
GROUP BY A.게시판ID, A.게시판명
ORDER BY A.게시판ID;
②
SELECT A.게시판ID, A.게시판명, COUNT(B.게시글ID) AS CNT
FROM 게시판 A LEFT OUTER JOIN 게시글 B
ON (A.게시판ID = B.게시판ID AND A.사용여부 = 'Y')
WHERE B.삭제여부 = 'N'
GROUP BY A.게시판ID, A.게시판명
ORDER BY A.게시판ID;
③
SELECT A.게시판ID, A.게시판명, COUNT(B.게시글ID) AS CNT
FROM 게시판 A LEFT OUTER JOIN 게시글 B
ON (A.게시판ID = B.게시판ID)
WHERE A.사용여부 = 'Y'
AND B.삭제여부 = 'N'
GROUP BY A.게시판ID, A.게시판명
ORDER BY A.게시판ID;
④
SELECT A.게시판ID, A.게시판명. COUNT(B.게시글ID) AS CNT
FROM 게시판 A RIGHT OUTER JOIN 게시글 B
ON (A.게시판ID = B.게시판ID AND A.사용여부 = 'Y' AND B.삭제여부 = 'N')
GROUP BY A.게시판ID, A.게시판명
ORDER BY A.게시판ID;
정답 : ① 해설 : 보기는 게시판별 게시글의 개수를 조회하는 SQL이다. 이때 게시글이 존재하지 않는 게시판도 조회되어야 한다. ORACLE 에서는 OUTER JOIN 구문을 (+) 기호를 사용하여 처리할 수도 있으며, 이를 ANSI 문장으로 변경하기 위해서는 INNER 쪽 테이블(게시글)에 조건절을 ON 절에 함께 위치시켜야 정상적인 OUTER JOIN을 수행할 수 있다. ②번의 경우는 OUTER 대상이 되는 테이블(게시판)의 조건절이 ON 절에 위치하였으므로 원하는 결과가 출력되지 않는다.
문제 14
Q. 다음과 같은 2개의 릴레이션이 있다고 가정하자. student의 기본키는 st_num이고, department의 기본키는 dept_num이다. 또한 student의 d_num은 department의 dept_num을 참조하는 외래키이다. 아래 SQL문의 실행 결과 건수는?
SELECT count(st_name)
FROM student s
WHERE not exists
(SELECT *
FROM department d
WHERE s.d_num = d.dept_num
and dept_name = '전자계산학과');
정답 : 5 해설 : 조건에 맞는 Student 데이터는 다음과 같다.
문제 15
Q. (SQL Server) 다음 중 아래의 SQL과 동일한 결과를 추출하는 SQL은? (단, 테이블 TAB1, TAB2의 PK 칼럼은 A, B이다.)
SELECT A, B
FROM TAB1
EXCEPT
SELECT A, B
FROM TAB2;
①
SELECT TAB2.A, TAB2.B
FROM TAB1, TAB2
WHERE TAB1.A <> TAB2.A
AND TAB1.B <> TAB2.B;
②
SELECT TAB1.A, TAB1.B
FROM TAB1
WHERE TAB1.A NOT IN (SELECT TAB2.A
FROM TAB2)
AND TAB1.B NOT IN (SELECT TAB2.B
FROM TAB2);
③
SELECT TAB2.A, TAB2.B
FROM TAB1, TAB2
WHERE TAB1.A = TAB2.A
AND TAB1.B = TAB2.B;
④
SELECT TAB1.A, TAB1.B
FROM TAB1
WHERE NOT EXISTS (SELECT 'X'
FROM TAB2
WHERE TAB1.A = TAB2.A
AND TAB1.B = TAB2.B);
정답 : ④ 해설 : EXCEPT는 차집합에 대한 연산이므로 NOT IN 또는 NOT EXISTS로 대체하여 처리가 가능하다. ②는 NOT IN을 사용하였으나, PK 칼럼 A, B에 대하여 각각 NOT IN 연산을 수행하여 다른 결과가 생성된다.
문제 16
Q. 아래와 같은 데이터 모델에 대해 SQL을 수행하였다. 다음 중 수행된 SQL과 동일한 결과를 도출하는 SQL은?
[수행 SQL]
SELECT A.서비스ID, B.서비스명, B.서비스URL
FROM (SELECT 서비스ID
FROM 서비스
INTERSECT
SELECT 서비스ID
FROM 서비스이용) A, 서비스 B
WHERE A.서비스ID = B.서비스 ID;
①
SELECT B.서비스ID, A.서비스명, A.서비스URL
FROM 서비스 A, 서비스이용 B
WHERE A.서비스ID = B.서비스ID;
②
SELECT X.서비스ID, X.서비스명, X.서비스URL
FROM 서비스 X
WHERE NOT EXISTS (SELECT 1
FROM (SELECT 서비스ID
FROM 서비스
MINUS
SELECT 서비스ID
FROM 서비스이용) Y
WHERE X.서비스ID = Y.서비스ID);
③
SELECT B.서비스ID, A.서비스명, A.서비스URL
FROM 서비스 A LEFT OUTER JOIN 서비스이용 B
ON (A.서비스ID = B.서비스ID)
WHERE B.서비스ID IS NULL
GROUP BY B.서비스ID, A.서비스명, A.서비스URL;
④
SELECT A.서비스ID, A.서비스명, A.서비스URL
FROM 서비스 A
WHERE 서비스ID IN (SELECT 서비스ID
FROM 서비스이용
MINUS
SELECT 서비스ID
FROM 서비스);
정답 : ② 해설 : 수행한 SQL은 이용된 적이 있었던 서비스를 추출하는 SQL이다. 전체 서비스에서 이용된 적이 있었던 서비스를 MINUS 하였으므로 이용된 적이 없었던 서비스가 서브쿼리에서 추출된다. 그러므로 NOT EXISTS 구문을 적용하면 이용된 적이 없었던 서비스가 출력된다.
문제 17
Q. SET OPERATOR 중에서 수학의 교집합과 같은 기능을 하는 연산자로 가장 적절한 것은?
① UNION ② INTERSECT ③ MINUS ④ EXCEPT
정답 : ② 해설 : 합집합(UNION), 교집합(INTERSECT), 차집합(MINUS/EXCEPT)
문제 18
Q. 다음 중 아래의 EMP 테이블의 데이터를 참조하여 실행한 SQL의 결과로 가장 적절한 것은?
SELECT ENAME AAA, JOB AAB
FROM EMP
WHERE EMPNO = 7369
UNION ALL
SELECT ENAME BBA, JOB BBB
FROM EMP
WHERE EMPNO = 7566
ORDER BY 1, 2;
①
②
③
④
정답 : ② 해설 : UNION ALL 을 사용하는 경우 칼럼 ALIAS는 첫번째 SQL 모듈 기준으로 표시되며, 정렬 기준은 마지막 SQL 모듈에 표시하면 된다.
문제 19
Q. 다음 중 아래 TBL1, TBL2 테이블에 대해 SQL을 수행한 결과인 것은?
SELECT COL1, COL2, COUNTS) AS CNT
FROM (SELECT COL1, COL2
FROM TBL1
UNION ALL
SELECT COL1, COL2
FROM TBL2
UNION
SELECT COL1, COL2
FROM TBL1)
GROUP BY COL1, COL2;
①
②
③
④
정답 : ① 해설 : 집합 연산자는 SQL에서 위에 정의된 연산자가 먼저 수행된다. 그러므로 UNION이 나중에 수행되므로 결과적으로 중복 데이터가 모두 제거되어 ①과 같은 결과가 도출된다. 만약 UNION과 UNION ALL의 순서를 바꾼다면 ②와 같은 결과가 도출된다.
문제 20
Q. 다음 중 아래에서 테이블 T1, T2에 대한 가, 나 두 개의 쿼리 결과 조회되는 행의 수로 가장 적절한 것은?
가.
SELECT A, B, C FROM R1
UNION ALL
SELECT A, B, C FROM R2
나.
SELECT A, B, C FROM R1
UNION
SELECT A, B, C FROM R2
① 가: 5개, 나: 3개 ② 가: 5개, 나: 5개 ③ 가: 3개, 나: 3개 ④ 가: 3개, 나: 5개
정답 : ① 해설 :
문제 21
Q. 다음 중 아래와 같은 집합이 존재할 때, 집합 A와 B에 대하여 집합 연산을 수행한 결과 집합 C가 되는 경우 이용되는 데이터베이스 집합 연산은?
집합A = {가, 나, 다, 라 }, 집합B = { 다, 라, 마, 바 }, 집합C = {다, 라 }
① UNION ② DIFFERENCE ③ INTERSECTION ④ PRODUCT
정답 : ③ 해설 : 집합 C는 집합 A와 집합 B의 교집합이며, 데이터베이스에서 교집합 기능을 하는 집합 연산은 INTERSECTION 이다.
문제 22
Q. 아래와 같은 데이터 모델에 대한 설명으로 가장 적절한 것은? (단, 시스템적으로 회원기본정보와 회원상세정보는 1:1, 양쪽 필수 관계임을 보장한다.)
① 회원ID 칼럼을 대상으로 (회원기본정보 EXCEPT 회원상세정보) 연산을 수행하면 회원상세정보가 등록되지 않은 회원ID가 추출된다. ② 회원ID 칼럼을 대상으로 (회원기본정보 UNION ALL 회원상세정보) 연산을 수행한 결과의 건수는 회원기본정보의 전체건수와 동일하다. ③ 회원ID 칼럼을 대상으로 (회원기본정보 INTERSECT 회원상세정보) 연산을 수행한 결과의 건수와 두 테이블을 회원ID로 JOIN 연산올 수행한 결과의 건수는 동일하다. ④ 회원ID 칼럼을 대상으로 (회원기본정보 INTERSECT 회원상세정보) 연산을 수행한 결과와 (회원기본정보 UNION 회원상세정보) 연산을 수행한 결과는 다르다.
정답 : ③ 해설 : ① 1:1, 양쪽 필수 관계를 시스템적으로 보장하므로 두 엔티티간의 EXCEPT 결과는 항상 공집합이다. ② 1:1, 양쪽 필수 관계를 시스템적으로 보장하므로 UNION을 수행한 결과는 회원기본정보의 전체 건수와 동일하지만, UNION ALL을 수행하였으므로 결과 건수는 회원기본정보의 전체건수의 2배가 된다. ④ 1:1, 양쪽 필수 관계를 시스템적으로 보장하므로 연산 수행 결과는 같다.
문제 23
Q. 아래와 같은 데이터 상황에서 아래의 SQL을 수행할 경우 정렬 순서상 2번째 표시될 값을 적으시오.
SELECT C3
FROM TAB1
START WITH C2 IS NULL
CONNECT BY PRIOR C1 = C2
ORDER SIBLINGS BY C3 DESC;
정답 : C
해설 : SQL의 실행 결과는 다음과 같다.
문제 24
Q. 다음 중 Oracle 계층형 질의에 대한 설명으로 가장 부적절한 것은?
① START WITH 절은 계층 구조의 시작점을 지정하는 구문이다. ② ORDER SIBLINGS BY절은 형제 노드 사이에서 정렬을 지정하는 구문이다. ③ 순방향 전개란 부모 노드로부터 자식 노드 방향으로 전개하는 것을 말한다. ④ 루트 노드의 LEVEL 값은 0이다.
정답 : ④ 해설 : Oracle 계층형 질의에서 루트 노드의 LEVEL 값은 1이다.
문제 25
Q. 다음 중 아래와 같은 사원 테이블에 대해서 SQL을 수행하였을 때의 결과로 가장 적절한 것은?
[SQL]
SELECT 사원번호, 사원명, 입사일자, 매니저사원번호
FROM 사원
START WITH 매니저사원번호 IS NULL
CONNECT BY PRIOR 사원번호 = 매니저사원번호
AND 입사일자 BETWEEN '2013-01-01' AND '2013-12-31'
ORDER SIBLINGS BY 사원번호;
①
②
③
④
정답 : ① 해설 : CONNECT BY 절에 작성된 조건절은 WHERE 절에 작성된 조건절과 다르다. START WITH 절에서 필터링된 시작 데이터는 결과 목록에 포함되어지며, 이후 CONNECT BY 절에 의해 필터링 된다. 그러므로 매니저 사원번호가 NULL인 데이터는 결과 목록에 포함되며, 이후 리커시브 조인에 의해 입사일자가 필터링 된다. ④번은 AND PRIOR 입사일자 BETWEEN ’2013-01-01’ AND '2013-12-31' 에 대한 결과이다.
문제 26
Q. 다음 중 계층형 질의문에 대한 설명으로 가장 부적절한 것은?
① SQL Server에서의 계층형 질의문은 CTE(Common Table Expression)를 재귀 호출함으로써 계충 구조를 전개한다. ② SQL Server에서의 계층형 질의문은 앵커 멤버를 실행하여 기본 결과 집합을 만들고 이후 재귀 멤버를 지속적으로 실행한다. ③ 오라클의 계충형 질의문에서 WHERE 절은 모든 전개를 진행한 이후 필터 조건으로서 조건을 만족하는 데이터만을 추출하는데 활용된다. ④ 오라클 계층형 질의문에서 PRIOR 키워드는 CONNECT BY 절에만 사용할 수 있으며, 'PRIOR 자식 = 부모' 형태로 사용하면 순방향 전개로 수행된다.
정답 : ④ 해설 : 오라클 계층형 질의문에서 PRIOR 키워드는 SELECT, WHERE 절에서도 사용할 수 있다.
문제 27
Q. 아래 [부서]와 [매출] 테이블에 대해서 SQL 문장을 실행하여 아래 [결과]와 같이 데이터가 추출되었다. 다음 중 동일한 결과를 추출하는 SQL 문장은?
①
SELECT A.부서코드, A.부서명, A.상위부서코드, B.매출액, LVL
FROM (SELECT 부서코드, 부서명, 상위부서코드, LEVEL AS LVL
FROM 부서
START WITH 부서코드 = '120'
CONNECT BY PRIOR 상위부서코드 = 부서코드
UNION
SELECT 부서코드, 부서명, 상위부서코드, LEVEL AS LVL
FROM 부서
START WITH 부서코드 = '120'
CONNECT BY 상위부서코드 = PRIOR 부서코드) A LEFT OUTER JOIN 매출 B
ON (A.부서코드 = B.부서코드)
ORDER BY A.부서코드;
②
SELECT A.부서코드, A.부서명, A.상위부서코드, B.매출액, LVL
FROM (SELECT 부서코드, 부서명, 상위부서코드, LEVEL AS LVL
FROM 부서
START WITH 부서코드 = '100'
CONNECT BY 상위부서코드 = PRIOR 부서코드) A LEFT OUTER JOIN 매출 B
ON (A.부서코드 = B.부서코드)
ORDER BY A.부서코드;
③
SELECT A.부서코드, A.부서명, A.상위부서코드, B.매출액, LVL
FROM (SELECT 부서코드, 부서명,상위부서코드, LEVEL AS LVL
FROM 부서
START WITH 부서코드 = '121'
CONNECT BY PRIOR 상위부서코드 = 부서코드) A LEFT OUTER JOIN 매출 B
ON (A.부서코드 = B.부서코드)
ORDER BY A.부서코드;
④
SELECT A.부서코드, A.부서명, A.상위부서코드, B.매출액, LVL
FROM (SELECT 부서코드, 부서명, 상위부서코드, LEVEL AS LVL
FROM 부서
START WITH 부서코드 = (SELECT 부서코드
FROM 부서
WHERE 상위부서코드 IS NULL
START WITH 부서코드 = '120'
CONNECT BY PRIOR 상위부서코드 = 부서코드)
CONNECT BY 상위부서코드 = PRIOR 부서코드) A LEFT OUTER JOIN 매출 B
ON (A.부서코드 = B.부서코드)
ORDER BY A.부서코드;
정답 : ① 해설 : 위의 결과는 중간 레벨인 도쿄지점(120)을 시작으로 상위의 전체 노드(역방향 전개)와 하위의 전체 노드(순방향 전개)를 검색하여 매출액을 추출하는 SQL이다. 부서 테이블의 전체 데이터를 보면 LEVEL은 1~3 까지 이지만, 추출된 데이터의 LEVEL은 1과 2만 추출된 것으로 보면 중간 LEVEL에서 추출된 것을 짐작할 수 있다.
문제 28
Q. 다음 중 SELF JOIN을 수행해야 할 경우로 가장 적절한 것은?
① 한 테이블 내에서 두 칼럼이 연관 관계가 있다. ② 두 테이블에 연관된 칼럼은 없으나 JOIN을 해야 한다. ③ 두 테이블에 공통 칼럼이 존재하고 두 테이블이 연관 관계가 있다. ④ 한 테이블 내에서 연관된 칼럼은 없으나 JOIN을 해야 한다.
정답 : ① 해설 : SELF JOIN은 하나의 테이블에서 두 개의 칼럼이 연관 관계를 가지고 있는 경우에 사용한다.
문제 29
Q. 아래와 같이 일자별매출 테이블이 존재할 때 아래 결과처럼 일자별 누적 매출액을 SQL로 구하려고 한다. WINDOW FUNCTION을 사용하지 않고 일자별 누적매출액을 구하는 SQL로 옳은 것은?
①
SELECT A.일자, SUM(A.매출액) AS 누적매출액
FROM 일자별매출 A
GROUP BY A.일자
ORDER BY A.일자;
②
SELECT B.일자, SUM(B.매출액) AS 누적매출액
FROM 일자별매출 A JOIN 일자별매출 B ON (A.일자 >= B.일자)
GROUP BY B.일자
ORDER BY B.일자;
③
SELECT A.일자, SUM(B.매출액) AS 누적매출액
FROM 일자별매출 A JOIN 일자별매출 B ON (A.일자 >= B.일자)
GROUP BY A.일자
ORDER BY A.일자;
④
SELECT A.일자, (SELECT SUM(B.매출액)
FROM 일자별매출 B WHERE B.일자 >= A.일자) AS 누적매출액
FROM 일자별매출 A
GROUP BY A.일자
ORDER BY A.일자;
정답 : ③
해설 : ① : 일자별매출액에 일자별 매출 테이블과 동일하게 출력된다. ②, ④ : 작은 날짜쪽에 제일 큰 누적금액이 출력된다.
문제 30
Q. 다음 중 아래의 SQL 수행 결과로 가장 적절한 것은?
SELECT COUNT(DISTINCT A || B)
FROM EMP
WHERE D = (SELECT D FROM DEPT WHERE E = 'i');
① 0 ② 1 ③ 2 ④ 3
정답 : ③ 해설 : WHERE 절의 단일행 서브쿼리인 (SELECT D FROM DEPT WHERE E = 'i') 에 의해서 DEPT 테이블의 D 칼럼 값이 x인 행이 선택되고. D = (SELECT D FROM DEPT WHERE E = 'i') 조건에 의해 EMP 테이블의 (A=1, B=a), (A=2, B=a)인 2건이 출력된다. 출력된 결과가 모두 UNIQUE 하기 때문에 DISTINCT 연산자는 결과 건수에 영향을 주지 않는다.
문제 31
Q. 아래는 서브쿼리에 대한 설명이다. 다음 중 올바른 것끼리 묶인 것은?
가) 서브쿼리는 단일 행(Single Row) 또는 복수 행(Multi Row) 비교 연산자와 함께 사용할 수 있다. 나) 서브쿼리는 SELECT 절, FROM 절, HAVING 절, ORDER BY 절 등에서 사용이 가능하다. 다) 서브쿼리의 결과가 복수 행(Multi Row) 결과를 반환하는 경우에는 '=', '<=', '=>' 등의 연산자와 함께 사용이 가능하다. 라) 연관(Correlated) 서브쿼리는 서브쿼리가 메인쿼리 컬럼을 포함하고 있는 형태의 서브쿼리이다. 마) 다중 칼럼 서브쿼리는 서브쿼리의 결과로 여러 개의 칼럼이 반환되어 메인쿼리의 조건과 동시에 비교되는 것을 의미하며 Oracle 및 SQL Server 등의 DBMS에서 사용할 수 있다.
① 나, 라, 마 ② 가, 나, 라 ③ 나, 다, 라 ④ 가, 나, 마
정답 : ② 해설 : 다) 서브쿼리의 결과가 복수 행 결과를 반환하는 경우에는 IN, ALL, ANY 등의 복수 행 비교 연산자와 사용하여야 한다. 마) 다중 컬럼 서브쿼리는 서브쿼리의 결과로 여러 개의 컬럼이 반환되어 메인 쿼리의 조건과 비교되는 데, SQL Server에서는 현재 지원하지 않는 기능이다.
문제 32
Q. 아래 테이블은 어느 회사의 사원들과 이들이 부양하는 가족에 대한 것으로 밑줄 친 칼럼은 기본키(Primary Key)를 표시한 것이다. 다음 중 '현재 부양하는 가족들이 없는 사원들의 이름을 구하라'는 질의에 대해 아래 SQL 문장의 ( ㄱ ), ( ㄴ )에 들어갈 내용으로 가장 적절한 것은?
[테이블]
사원 (사번, 이름, 나이) 가족 (이름, 나이, 부양사번) ※ 가족 테이블의 부양사번은 사원 테이블의 사번을 참조하는 외래 키(Foreign Key)이다.
[SQL 문장]
SELECT 이름
FROM 사원
WHERE ( ㄱ ) (SELECT * FROM 가족 WHERE ( ㄴ ))
정답 : ③ 해설 : '현재 부양하는 가족들이 없는 사원들의 이름을 구하라'를 구현하는 방법은 가족 테이블에 부양사번이 없는 사원 이름을 사원 테이블에서 추출하면 되고, SQL 문장으로 NOT EXISTS, NOT IN, LEFT OUTER JOIN을 사용하여 구현할 수 있다.
문제 33
Q. 다음 중 아래의 ERD를 참조하여 아래 SQL과 동일한 결과를 출력하는 SQL로 가장 부적절한 것은?
[SQL]
SELECT A.회원번호, A.회원명
FROM 회원 A, 동의항목 B
WHERE A.회원번호 = B.회원번호
GROUP BY A.회원번호, A.회원명
HAVING COUNT(CASE WHEN B.동의여부 = 'N' THEN 0 ELSE NULL END) >= 1
ORDER BY A.회원번호;
①
SELECT A.회원번호, A.회원명
FROM 회원 A
WHERE EXISTS (SELECT 1 FROM 동의항목 B
WHERE A.회원번호 = B.회원번호 AND B.동의여부 = 'N')
ORDER BY A.회원번호;
②
SELECT A.회원번호, A.회원명
FROM 회원 A
WHERE A.회원번호 IN (SELECT B.회원번호 FROM 동의항목 B
WHERE B.동의여부 = 'N')
ORDER BY A.회원번호;
③
SELECT A.회원번호, A.회원명
FROM 회원 A
WHERE 0 < (SELECT COUNT(*)
FROM 동의항목 B WHERE B.동의여부 = 'N')
ORDER BY A.회원번호;
④
SELECT A.회원번호, A.회원명
FROM 회원 A, 동의항목 B
WHERE A.회원번호 = B.회원번호 AND B.동의여부 = 'N'
GROUP BY A.회원번호, A.회원명
ORDER BY A.회원번호;
정답 : ③ 해설 : 위의 SQL은 약관항목 중 단 하나라도 동의를 하지 않은 회원을 구하는 SQL이다. HAVING 절에서 동의여부가 N인 데이터가 한 건이라도 존재하는 데이터를 추출한다. ③의 회원 테이블과 동의항목 테이블간에 회원번호 칼럼으로 연관 서브쿼리로 처리되어야 정상적으로 처리할 수 있다.
문제 34
Q. 아래의 데이터 모델을 기준으로 SQL을 작성하였다. 다음 중 아래의 SQL에 대해 가장 바르게 설명한 것은?
[SQL]
SELECT A.회원ID, A.회원명, A.이메일
FROM 회원 A
(ㄱ)
WHERE EXISTS (SELECT 'X'
FROM 이벤트 B, 메일발송 C
WHERE B.시작일자 >= '2014.10.01'
AND B.이벤트ID = C.이벤트ID
(ㄴ)
AND A.회원ID = C.회원ID
(ㄷ)
HAVING COUNT(*) < (SELECT COUNT(*)
FROM 이벤트
WHERE 시작일자 >= '2014.10.01'));
① 이벤트 시작일자가 '2014.10.01'과 같거나 큰 이벤트를 대상으로 이메일이 발송된 기록이 있는 모든 회원을 추출하는 SQL이다. ② (ㄴ)을 제거하고 (ㄱ)의 EXISTS 연산자를 IN연산자로 변경해도 그 결과는 동일하다. ③ (ㄷ)은 이벤트 시작일자가 '2014.10.01'과 같거자 큰 이벤트 건수와 그 이벤트들을 기준으로 회원별 이메일 발송건수를 비교하는 것이다. ④ GROUP BY 및 집계 함수를 사용하지 않고 HAVING 절을 사용하였으므로 SQL이 실행되지 못하고 오류가 발생한다.
정답 : ③ 해설 : 이벤트 시작일자가 *2014.10.01’과 같거나 큰 이벤트를 기준으로 단 한차례라도 이메일 발송이 누락된 회원을 추출하는 SQL 문장이다. (ㄴ)을 제거하고 (ㄱ)의 EXISTS 연산자를 IN연산자로 변경하게 되면 회원별로 메일을 발송한 건수를 계산할 수 없으므로 원하는 결과를 추출할 수 없다. GROUP BY 및 집계 함수를 사용하지 않고 HAVING 절을 사용하였다고 하여 SQL 문장이 오류가 발생하지는 않는다.
문제 35
Q. 다음 중 서브쿼리에 대한 설명으로 가장 적절한 것은?
① 단일 행 서브쿼리는 서브쿼리의 실행 결과가 항상 한 건 이하인 서브쿼리로서 IN, ALL 등의 비교 연산자를 사용하여야 한다. ② 다중 행 서브쿼리 비교 연산자는 단일 행 서브쿼리의 비교 연산자로도 사용할 수 있다. ③ 연관 서브쿼리는 주로 메인쿼리에 값을 제공하기 위한 목적으로 사용한다. ④ 서브 쿼리는 항상 메인쿼리에서 읽혀진 데이터에 대해 서브쿼리에서 해당 조건이 만족하는지를 확인하는 방식으로 수행된다
정답 : ② 해설 : ① 단일 행 서브쿼리의 비교연산자로는 =, <, <=, >, >=, <>가 되어야 한다. IN, ALL 등의 비교연산자는 다중 행 서브쿼리의 비교연산자 이다. ② 단일 행 서브쿼리의 비교연산자는 다중 행 서브쿼리의 비교연산자로 사용할 수 없지만. 반대의 경우는 가능하다. ③ 비 연관 서브쿼리가 주로 메인쿼리에 값을 제공하기 위한 목적으로 사용된다. ④ 메인 쿼리의 결과가 서브쿼리로 제공될 수도 있고. 서브쿼리의 결과가 메인쿼리로 제공될 수도 있으므로 실행 순서는 상황에 따라 달라진다.
문제 36
Q. 다음 중 아래 SQL에 대한 설명으로 가장 부적절한 것은?
[SQL]
SELECT B.사원번호, B.사원명, A.부서번호, A.부서명,
SELECT COUNT(*) FROM 부양가족 Y WHERE Y.사원번호 = B.사원번호) AS 부양가족수
FROM 부서 A, (SELECT *
FROM 사원
WHERE 입사년도 = '2014') B
WHERE A.부서번호 = B.부서번호
AND EXISTS (SELECT 1 FROM 사원 X WHERE X.부서번호 = A.부서번호);
① 위 SQL에는 다중 행 연관 서브쿼리, 단일 행 연관 서브쿼리, Inline View 가 사용되었다. ② SELECT 절에 사용된 서브쿼리는 스칼라 서브쿼리라고도 하며, 이러한 형태의 서브쿼리는 JOIN으로 동일한 결과를 추출할 수도 있다. ③ WHERE 절의 서브쿼리에 사원 테이블 검색 조건으로 입사년도 조건을 FROM절의 서브쿼리와 동일하게 추가해야 원하는 결과를 추출할 수 있다. ④ FROM 절의 서브쿼리는 동적 뷰(Dynamic View)라고도 하며, SQL 문장 중 테이블 명이 올 수 있는 곳에서 사용할 수 있다.
정답 : ③ 해설 : 2014년에 입사한 사원들의 사원, 부서 정보와 부양가족수를 추출하는 SQL이다. SELECT 절에 사용된 서브쿼리는 단일행 연관 서브쿼리로 JOIN으로도 변경이 가능하며, FROM 절에 사용된 서브쿼리는 Inline View 또는 Dynamic View 이고, WHERE 절에 사용된 서브쿼리는 다중 연관 서브쿼리이다. ③ 이미 FROM 절에 Inline View로 사원 테이블의 입사년도 조건을 명시하였으므로 WHERE 절의 EXISTS 조건은 부서와 사원 테이블 간의 JOIN 조건에 의해 결과에 어떠한 영향도 미치지 못하므로 삭제해도 무방하다.
문제 37
Q. 아래와 같은 데이터 모델에서 평가대상상품에 대한 품질평가항목별 최종 평가 결과를 추출하는 SQL 문장으로 옳은 것은? (단, 평가항목에 대한 평가(평가등급)가 기대수준에 미치지 못할 경우 해당 평가항목에 대해서만 재평가를 수행한다.)
①
SELECT B.상품ID, B.상품명, C.평가항목ID, C.평가항목명, A.평가회차, A.평가등급, A.평가일자
FROM 평가결과 A, 평가대상상품 B, 품질평가항목 C,
(SELECT MAX(평가회차) AS 평가회차 FROM 평가결과) D
WHERE A.상품ID = B.상품ID
AND A.평가항목ID = C.평가항목ID
AND A.평가회차 = D.평가회차;
②
SELECT B.상품ID, B.상품명, C.평가항목ID, C.평가항목명, A.평가회차, A.평가등급, A.평가일자
FROM 평가결과 A, 평가대상상품 B, 품질평가항목 C
WHERE A.상품ID = B.상품ID
AND A.평가항목ID = C.평가항목ID
AND A.평가회차 = (SELECT MAX(X.평가회차)
FROM 평가결과 X
WHERE X.상품ID = B.상품ID
AND X.평가항목ID = C.평가항목ID;
③
SELECT B.상품ID, B.상품명.C, 평가항목ID, C.평가항목명,
MAX(A.평가회차) AS 평가회차,
MAX(A.평가등급) AS 평가등급,
MAX(A.평가일자) AS 평가일자
FROM 평가결과 A, 평가대상상품 B, 품질평가항목 C
WHERE A.상품ID = B.상품ID
AND A.평가항목 = C.평가항목ID
GROUP BY B.상품ID, B.상품명, C.평가항목ID, C.평가항목명;
④
SELECT B.상품ID, B.상품명, C.평가항목ID, C.평가항목명, A.평가회차, A.평가등급, A.평가일자
FROM (SELECT 상품ID, 평가항목ID, MAX(평가회차) AS 평가회차,
MAX(평가등급) AS 평가등급, MAX(평가일자) AS 평가일자
FROM 평가결과
GROUP BY 상품ID, 평가항목ID) A, 평가대상상품 B, 품질평가항목 C
WHERE A.상품ID = B.상품ID
AND A.평가항목ID = C.평가항목ID;
정답 : ② 해설 : 연관 서브쿼리를 활용하여 특정 상품, 평가항목별로 최종 평가회차와 Join을 수행하여 원하는 결과를 출력한다.
문제 38
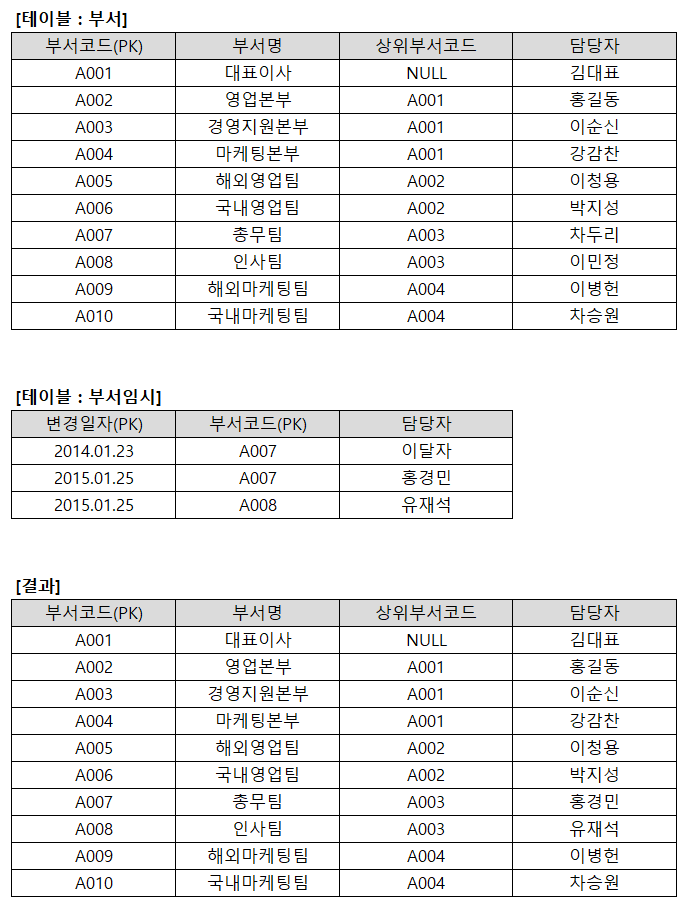
Q. 아래 부서 테이블의 담당자 변경을 위해 부서임시 테이블에 입력된 데이터를 활용하여 주기적으로 부서 테이블을 아래 결과와 같이 반영하기 위한 SQL으로 가장 적절한 것은? (단, 부서임시 테이블에서 변경일자를 기준으로 가장 최근에 변경된 데이터를 기준으로 부서 테이블에 반영되어야 한다.)
①
UPDATE 부서 A SET 담당자 = (SELECT C.부서코드
FROM (SELECT 부서코드, MAX(변경일자) AS 변경일자
FROM 부서임시
GROUP BY 부서코드) B, 부서임시 C
WHERE B.부서코드 = C.부서코드
AND B.변경일자 = C.변경일자
AND A.부서코드 = C.부서코드);
②
UPDATE 부서 A SET 담당자 = (SELECT C.부서코드
FROM (SELECT 부서코드, MAX(변경일자) AS 변경일자
FROM 부서임시
GROUP BY 부서코드) B, 부서임시 C
WHERE B.부서코드 = C.부서코드
AND B.변경일자 = C.변경일자
AND A.부서코드 = C.부서코드)
WHERE EXISTS (SELECT 1 FROM 부서 X WHERE A.부서코드 = X.부서코드);
③
UPDATE 부서 A SET 담당자 = (SELECT B.담당자
FROM 부서임시 B
WHERE B.부서코드 = A.부서코드
AND B.변경일자 = (SELECT MAX(C.변경일자)
FROM 부서임시 C
WHERE C.부서코드 = B.부서코드))
WHERE 부서코드 IN (SELECT 부서코드 FROM 부서임시);
④
UPDATE 부서 A SET 담당자 = (SELECT B.담당자
FROM 부서임시 B
WHERE B.부서코드 = A.부서코드
AND B.변경일자 = '2015.01.25.');
정답 : ③ 해설 : ① 연관 서브쿼리를 활용한 UPDATE에서 WHERE 절은 UPDATE 대상이 되는 데이터의 범위를 결정하게 되는데, WHERE 절이 누락되어 부서의 모든 데이터가 UPDATE 대상이 되므로 부서코드 A007, A008을 제외한 모든 데이터가 NULL 값으로 변경된다. ② WHERE 절 조건이 부서임시가 아닌 부서 테이블이므로 A007, A008을 제외한 모든 데이터가 NULL 값으로 변경된다. ④ ①과 같은 사유로 부서코드 A007, A008을 제외한 모든 데이터가 NULL 값으로 변경된다. 또한 변경일자를 하드 코딩하는 것은 답이 될 수 없다.
문제 39
Q. 다음 중 뷰(View)에 대한 설명으로 가장 부적절한 것은?
① 뷰는 단지 정의만을 가지고 있으며. 실행 시점에 질의를 재작성하여 수행한다. ② 뷰는 복잡한 SQL 문장을 단순화 시켜주는 장점이 있는 반면, 테이블 구조가 변경되면 응용 프로그램을 변경해 주어야 한다. ③ 뷰는 보안을 강화하기 위한 목적으로도 활용할 수 있다. ④ 실제 데이터를 저장하고 있는 뷰를 생성하는 기능을 지원하는 DBMS도 있다.
정답 : ② 해설 : 뷰의 장점 중 독립성은 테이블 구조가 변경되어도 뷰를 사용하는 응용 프로그램은 변경하지 않아도 된다.
문제 40
Q. 아래 테이블에 대한 [뷰 생성 스크립트]를 실행한 후, 조회 SQL의 실행 결과로 맞는 것은?
[뷰 생성 스크립트]
CREATE VIEW V_TBL
AS
SELECT *
FROM TBL
WHERE C1 = 'B' OR C1 IS NULL;
[조회 SQL]
SELECT SUM(C2) C2
FROM V_TBL
WHERE C2 >= 200 AND C1 = 'B';
① 0 ② 200 ③ 300 ④ 400
정답 : ② 해설 : 조회 SQL 실행 시 V_TBL은 뷰 스크립트로 치환되어 수행된다. 뷰 생성 스크립트에서 부여된 조건과 조회 SQL에서 부여된 조건 모두를 만족해야 한다.
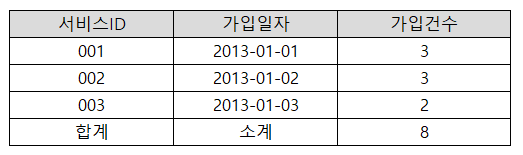
문제 41
Q. 다음 중 아래의 테이블에서 SQL을 실행할 때 결과로 가장 적절한 것은?
[SQL]
SELECT CASE WHEN GROUPING(A.서비스ID) = 0 THEN A.서비스ID ELSE '합계' END AS 서비스ID,
CASE WHEN GROUPING(B.가입일자) = 0 THEN NVL(B.가입일자, '-') ELSE '소계' END AS 가입일자,
COUNT(B.회원번호) AS 가입건수
FROM 서비스 A LEFT OUTER JOIN 서비스가입 B
ON (A.서비스ID = B.서비스ID AND B.가입일자 BETWEEN '2013-01-01' AND '2013-01-31')
GROUP BY ROLLUP(A.서비스ID, B.가입일자);
①
②
③
④
정답 : ③ 해설 : ROLLUP은 계층 구조를 가진 SUB TOTAL을 생성하는 함수로, 나열된 칼럼의 순서가 변경되면 수행 결과도 변경된다. 위의 SQL 문장은 서비스ID에 대해서 가입입자별 가입건수 및 소계와 전체 가입건수를 구하되 OUTER JOIN을 수행하였으므로 가입내역이 없는 서비스ID(004)에 대해서도 SUB TOTAL을 출력하고 있다.
문제 42
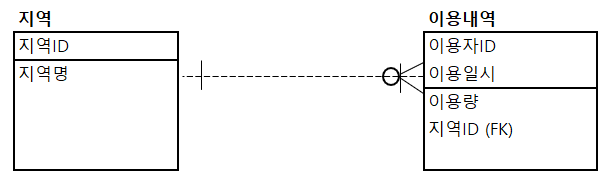
Q. 아래의 데이터 모델에서 SQL을 이용하여 표(지역별 월별 이용량)와 같은 형식의 데이터를 추출하려고 할 때 올바른 SQL 문장은?
①
SELECT (CASE GROUPING(B.지역명) WHEN 0 THEN '지역전체' ELSE B.지역명 END) AS 지역명,
(CASE GROUPING(TO_CHAR(A.이용일시, 'YYYY.MM'))
WHEN 0 THEN '월별합계'
ELSE T0_CHAR(A.이용일시, 'YYYY.MM') END) AS 이용월,
SUM(A.이용량 AS) 이용량
FROM 이용내역 A INNER JOIN 지역 B ON (A.지역ID = B.지역ID)
GROUP BY ROLLUP(B.지역명, TO_CHAR(A.이용일시, 'YYYY.MM'));
②
SELECT (CASE GROUPING(B.지역ID) WHEN 1 THEN '지역전체' ELSE MIN(B.지역명) END) AS 지역명,
(CASE GROUPING(TO_CHAR(A.이용일시, 'YYYY.MM'))
WHEN 1 THEN '월별합계'
ELSE TO_CHAR(A.이용일시, 'YYYY.MM') END) AS 이용월,
SUM(A.이용량) AS 이용량
FROM 이용내역 A INNER JOIN 지역 B ON (A.지역ID = B.지역ID)
GROUP BY ROLLUP(B.지역ID, TO_CHAR(A.이용일시, 'YYYY.MM'));
③
SELECT (CASE GROUPING(B, 지역명) WHEN 1 THEN '지역전체' ELSE B.지역명 END) AS 지역명,
(CASE GROUPING(TO_CHAR(A.이용일시, 'YYYY.MM'))
WHEN 1 THEN '월별합계'
ELSE TO_CHAR(A.이용일시, 'YYYY.MM') END) AS 이용월,
SUM(A.이용량) AS 이용량
FROM 이용내역 A INNER JOIN 지역 B ON (A.지역ID = B.지역ID)
GROUP BY CUBE(B.지역명, TO_CHAR(A.이용일시, 'YYYY.MM'));
④
SELECT (CASE GROUPING(B, 지역ID) WHEN 1 THEN '지역전체' ELSE MIN(B.지역명) END) AS 지역명,
(CASE GROUPING(TO_CHAR(A.이용일시, 'YYYY.MM'))
WHEN 1 THEN '월별합계'
ELSE TO_CHAR(A.이용일시, 'YYYY.MM') END) AS 이용월,
SUM(A.이용량) AS 이용량
FROM 이용내역 A INNER JOIN 지역 B ON (A.지역ID = B.지역ID)
GROUP BY GROUPING SETS(B.지역ID, TO_CHAR(A.이용일시, 'YYYY.MM'));
정답 : ② 해설 : 위의 결과 데이터는 지역에 대해서 월별 이용량 및 소계와 전체 이용량을 출력하였으므로, ROLLUP 함수를 할용할 수 있다. ROLLUP 집계 그룹 함수는 나열된 칼럼에 대해 계층 구조로 집계를 출력하는 함수로써 ROLLUP(A, B)를 수행하면 (A, B)별 집계, A별 집계와 전체 집계를 출력할 수 있다. ① CASE 절의 GROUPING 함수의 사용이 잘못되었다. (0이 아닌 1이 되어야 한다.
문제 43
Q. 아래 결과를 얻기 위한 SQL문에서 ( ㄱ ) 에 들어갈 함수를 작성하시오.
[SQL문]
SELECT 구매고객, 구매월, COUNT(*) "총 구매건", SUM(구매금액) '총 구매액'
FROM 구매이력
GROUP BY ( ㄱ )(구매고객, 구매월)
정답 : ROLLUP 해설 : 위 SQL의 결과는 (구매고객, 구매월)별, 구매고객별 그리고 전체에 대한 구매건수와 구매금액을 출력한 결과이다. 집계에 계층 구조가 있으므로 나열된 칼럼에 대해 계층 구조로 집계를 출력하는 ROLLUP을 사용하여 집계 SQL을 작성할 수 있다.
문제 44
Q. 다음 설명 중 가장 적절한 것은?
① 일반 그룹 함수를 사용하여 CUBE, GROUPING SETS와 같은 그룹 함수와 동일한 결과를 추출할 수 있으나, ROLLUP 그룹 함수와 동일한 결과는 추출할 수 없다. ② GROUPING SETS 함수의 경우에는 함수의 인자로 주어진 칼럼의 순서에 따라 결과가 달라지므로 컬럼의 순서가 중요하다. ③ CUBE, ROLLUP, GROUPING SETS 함수들의 대상 칼럼 중 집계된 컬럼 이외의 대상 칼럼 값은 해당 컬럼의 데이터 중 가장 작은 값을 반환한다. ④ CUBE 그룹 함수는 인자로 주어진 칼럼의 결합 가능한 모든 조합에 대해서 집계를 수행하므로 다른 그룹 함수에 비해 시스템에 대한 부하가 크다.
정답 : ④ 해설 : ① CUBE, GROUPING SETS, ROLLUP 세 가지 그룹 함수 모두 일반 그룹 함수로 동일한 결과를 출력할 수 있다. ② 함수의 인자로 주어진 칼럼의 순서에 따라 다른 결과를 추출하게 되는 그룹 함수는 ROLLUP 이며, 나열된 칼럼에 대해 계층 구조로 집계를 출력한다. ③ CUBE, ROLLUP, GROUPING SETS 함수들에 의해 집계된 레코드에서 집계 대상 칼럼 이외의 GROUP 대상 칼럼의 값은 NULL을 반환한다.
문제 45
Q. 아래와 같이 설비와 에너지사용 테이블을 이용하여 결과를 나타내려할 때 SQL으로 가장 적절한 것을 2개 고르시오.
①
SELECT A.설비, B.에너지코드, SUM(B.사용량) AS 사용량합계
FROM 설비 A INNER JOIN 에너지사용량 B
ON (A.설비ID = B.설비ID)
GROUP BY CUBE ((A.설비ID), (B.에너지코드), (A.설비ID, B.에너지코드))
ORDER BY A.설비ID, B.에너지코드;
②
SELECT A.설비, B.에너지코드, SUM(B.사용량) AS 사용량합계
FROM 설비 A INNER JOIN 에너지사용량 B
ON (A.설비ID = B.설비ID)
GROUP BY CUBE (A.설비ID, B.에너지코드)
ORDER BY A.설비ID, B.에너지코드;
③
SELECT A.설비, B.에너지코드, SUM(B.사용량) AS 사용량합계
FROM 설비 A INNER JOIN 에너지사용량 B
ON (A.설비ID = B.설비ID)
GROUP BY GROUPING SETS((A.설비ID), (B.에너지코드), (A.설비ID, B.에너지코드), 0)
ORDER BY A.설비ID, B.에너지코드;
④
SELECT A.설비, B.에너지코드, SUM(B.사용량) AS 사용량합계
FROM 설비 A INNER JOIN 에너지사용량 B
ON (A.설비ID = B.설비ID)
GROUP BY GROUPING SETS((A.설비ID), (B.에너지코드), (A.설비ID, B.에너지코드))
ORDER BY A.설비ID, B.에너지코드;
정답 : ②, ③ 해설 : SQL의 결과를 보면 설비ID와 에너지코드의 모든 조합에 대하여 사용량합계를 추출하고 있다. CUBE 함수는 인수로 나열된 항목의 가능한 모든 조합에 대하여 GROUPING을 수행한다. 또한 GROUPING SETS은 사용자가 원하는 다양한 조합을 인수로 사용할 수 있다. 위 문제에서 ②번은 CUBE를 사용하였으므로 CUBE 절에 나열된 칼럼의 모든 조합 즉, ((설비ID), (에너지코드), (설비ID, 에너지코드))에 대해 SUB TOTAL을 만들게 된다. ③번은 GROUPING SETS를 할용하여 ②번의 모든 조합을 직접 기술하였다.
문제 46
Q. 자재발주 테이블에 SQL을 수행하여 아래와 같은 결과를 얻었다. 다음 중 ( ㄱ )에 들어갈 문장으로 옳은 것은?
[SQL]
SELECT CASE WHEN GROUPING(자재번호) = 1 THEN '자재전체' ELSE 자재번호 END AS 자재번호,
CASE WHEN GROUPING(발주처ID) = 1 THEN '발주처전체' ELSE 발주처ID END AS 발주처ID,
CASE WHEN GROUPING(발주일자) = 1 THEN '발주일자전체' ELSE 발주일자 END AS 발주일자,
SUM(발주수량) AS 발주수량합계
FROM 자재발주
( ㄱ )
ORDER BY 자재번호, 발주처ID, 발주일자;
① GROUP BY CUBE (자재번호, (발주처ID, 발주일자)) ② GROUP BY CUBE (자재번호, 발주처ID, 발주일자) ③ GROUP BY GROUPING SETS (자재번호, 발주처ID, 발주일자) ④ GROUP BY GROUPING SETS (자재번호, (발주처ID, 발주일자))
정답 : ④ 해설 : 집계 그룹 함수에는 ROLLUP, CUBE, GROUPING SETS 함수가 있다. 문제의 결과 데이터는 (자재번호별) SUB TOTAL과 (자재번호, 발주처별) SUB TOTAL을 출력하고 있다. GROUPING SETS 함수를 사용하여 입력된 인수들에 대한 개별 집계를 구할 수 있으며, CUBE 함수의 경우는 나열된 모든 인수의 결합 가능한 집계가 출력된다. 그러므로 위의 문제에서는 GROUP BY GROUPING SETS(자재번호, (발주처ID, 발주일자))가 되어야 한다.
문제 47
Q. 다음 중 월별매출 테이블을 대상으로 아래 SQL을 수행한 결과인 것은?
[SQL]
SELECT 상품ID, 월, SUM(매출액) AS 매출액
FROM 월별매출
WHERE 월 BETWEEN '2014.10' AND '2014.12'
GROUP BY GROUPING SETS((상품ID, 월));
① ② ③ ④
정답 : ② 해설 : GROUPING SETS 함수는 표시된 인수들에 대한 개별 집계를 구하는 기능을 하며, 위의 SQL은 (상품ID, 월)별 집계 데이터를 출력한다.
문제 48
Q. 다음 중 윈도우 함수(Window Function, Analytic Function)에 대한 설명으로 가장 부적절한 것은?
① Partition과 Group By 구문은 의미적으로 유사하다. ② Partition 구문이 없으면 전체 집합을 하나의 Partition으로 정의한 것과 동일하다. ③ 윈도우 함수 처리로 인해 결과 건수가 줄어든다. ④ 윈도우 함수 적용 범위는 Partition을 넘을 수 없다.
정답 : ③ 해설 : 윈도우 함수는 결과에 대한 함수 처리이기 때문에 결과 건수는 줄지 않는다.
문제 49
Q. 다음 중 아래와 같은 테이블에서 SQL을 실행할 때 결과로 가장 적절한 것은?
[SQL]
SELECT 고객번호, 고객명, 매출액, RANK() OVER(ORDER BY 매출액 DESC) AS 순위
FROM (
SELECT A.고객번호, MAX(A.고객명) AS 고객명, SUM(B.매출액) AS 매출액
FROM 고객 A INNER JOIN 월별매출 B
ON (A.고객번호 = B.고객번호)
GROUP BY A.고객번호
)
ORDER BY RNK;
① ② ③ ④
정답 : ① 해설 : 위의 SQL은 고객별 매출액과 매출 순위를 구하되 동일 순위일 경우 중간 순위를 비워둔 데이터를 추출한다. 순위를 구하는 함수로는 RANK, DENSE_RANK, ROW_NUMBER 함수가 있다. RANK WINDOW FUNCTION은 동일 값에 대해서는 동일 순위를 부여하고, 중간 순위는 비워 두지만, DENSE_RANK 함수는 동일 순서를 부여하되 중간 순위를 비우지 않는다. ROW_NUMBER 함수는 동일 값에 대해서도 유일한 순위를 부여한다.
문제 50
Q. 아래 데이터 모델에서 활동점수가 높은 고객을 게임상품ID별로 10등까지 선별하여 사은행사를 진행하려고 한다. 다음 SQL 중, 가장 적절한 것은? (단, 활동점수가 동일한 고객은 동일등수로 한다. 아래 결과 예제 참조)
①
SELECT 게임상품ID, 고객ID, 활동점수, 순위
FROM (SELECT DENSE_RANK() OVER(ORDER BY 활동점수 DESC) AS 순위, 고객ID, 게임상품ID, 활동점수
FROM 고객활동)
WHERE 순위 <= 10;
②
SELECT 게임상품ID, 고객ID, 활동점수, 순위
FROM (SELECT DENSE_RANK() OVER(PARTITION BY 게임상품ID ORDER BY 활동점수 DESC) AS 순위,
고객ID, 게임상품ID, 활동점수
FROM 고객활동)
WHERE 순위 <= 10;
③
SELECT 게임상품ID, 고객ID, 활동점수, 순위
FROM (SELECT RANK() OVER(ORDER BY 활동점수 DESC) AS 순위, 고객ID, 게임상품ID, 활동점수
FROM 고객활동)
WHERE 순위 <= 10;
④
SELECT 게임상품ID, 고객ID, 활동점수, 순위
FROM (SELECT RANK() OVER(PARTITION BY 게임상품ID ORDER BY 활동점수 DESC) AS 순위,
고객ID, 게임상품ID, 활동점수
FROM 고객활동);
정답 : ④ 해설 : 게임상품별로 고객 목록을 추출하기 위해서는 OVER 절에 'PARTITION BY 게임상품ID' 를 적용하여 게임상품별 활동점수로 순위가 추출될 수 있도록 하여야 한다. RANK WINDOW 함수는 OVER 절의 ORDER BY에 대한 결과에 따라 동일한 값을 동일한 등수로 처리함과 동시에 중간 순위를 비우는 반면, DENSE_RANK WINDOW 함수는 중간 순위를 비우지 않는다.
문제 51
Q. 다음 중 추천내역 테이블에서 아래와 같은 SQL을 수행하였을 때의 결과로 가장 적절한 것은?
[SQL]
SELECT 추천경로, 추천인, 피추천인, 추천점수
FROM (SELECT 추천경로, 추천인, 피추천인, 추천점수,
ROW_NUMBER() OVER(PARTITION BY 추천경로 ORDER BY 추천점수 DESC) AS RNUM
FROM 추천내역)
WHERE RNUM = 1;
① ② ③ ④
정답 : ③ 해설 : ROW_NUMBER 함수는 ORDER BY 절에 의해 정렬된 데이터에 동일 값이 존재하더라도 유일한 순위를 부여하는 함수로서 데이터 그룹 내에 유일한 순위를 추출할 때 사용할 수 있는 함수이다. 문제의 SQL은 추천경로별(PARTION BY 추천경로)로 추천점수가 가장 높은(ORDER BY 추천점수 DESC) 데이터를 한 건씩만 출력한다.
문제 52
Q. 다음 중 아래의 SQL에 대한 설명으로 가장 적절한 것은?
[SQL]
SELECT 상품분류코드, AVG(상품가격) AS 상품가격,
COUNT(*) OVER(ORDER BY AVG(상품가격) RANGE BETWEEN 10000 PRECEDING
AND 10000 FOLLOWING) AS 유사개수
FROM 상품
GROUP BY 상품분류코드;
① WINDOW FUNCTION을 GROUP BY 절과 함께 사용하였으므로 위의 SQL은 오류가 발생한다. ② WINDOW FUNCTION의 ORDER BY 절에 AVG 집계 함수를 사용하였으므로 위의 SQL은 오류가 발생한다. ③ 유사개수 칼럼은 상품분류코드별 평균상품가격을 서로 비교하여 -10000 ~ +10000 사이에 존재하는 상품분류코드의 개수를 구한 것이다. ④ 유사개수 칼럼은 상품전체의 평균상품가격을 서로 비교하여 -10000 ~ +10000 사이에 존재하는 상품의 개수를 구한 것이다.
정답 : ③ 해설 : GROUP BY 절의 집합을 원본으로 하는 데이터를 WINDOW FUNCTION과 함께 사용한다면 GROUP BY 절과 함께 WINDOW FUNCTION을 사용한다고 하더라도 오류가 발생하지 않으며, 유사개수 칼럼은 상품분류코드로 GROUPING된 집합을 원본 집합으로 하여 상품분류코드별 평균상품가격을 서로 비교하여 현재 읽혀진 상품분류코드의 평균 가격 대비 -10000 ~ +10000 사이에 존재하는 상품분류코드의 개수를 구한 것이다.
문제 53
Q. 다음 중 [사원] 테이블에 대하여 아래와 같은 SQL을 수행하였을 때 예상되는 결과로 가장 적절한 것은?
[SQL]
SELECT Y.사원ID, Y.부서ID, Y.사원명, Y.연봉
FROM (SELECT 사원ID, MAX(연봉) OVER(PARTITION BY 부서ID) AS 최고연봉
FROM 사원) X, 사원 Y
WHERE X.사원ID = Y.사원ID
AND X.최고연봉 = Y.연봉;
① ② ③ ④
정답 : ① 해설 : 안쪽 IN-LINE VIEW에 의해 아래와 같이 사원ID와 부서별 최고연봉이 결과로 생성되며,
이를 다시 사원 테이블과 사원ID = 사원ID AND 최고연봉 = 연봉 으로 JOIN을 하게 되면 부서별 최고연봉의 사원이 출력된다.
문제 54
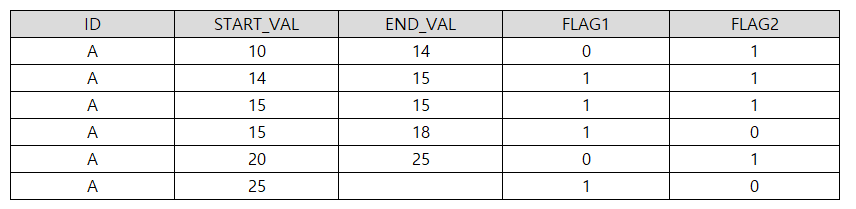
Q. 다음 중 아래 SQL의 실행 결과로 가장 적절한 것은?
CREATE TABLE TBL
(ID VARCHAR2(10),
START_VAL NUMBER,
END_VAL NUMBER)
SELECT ID, START_VAL, END_VAL
FROM (
SELECT ID, START_VAL, NVL(END_VAL, 99) END_VAL,
(CASE WHEN START_VAL = LAG(END_VAL) OVER (PARITTION BY ID
ORDER BY START_VAL, NVL(END_VAL, 99)) THEN 1 ELSE 0
END) FLAG1,
(CASE WHEN END_VAL = LEAD(START_VAL) OVER (PARTITION BY ID
ORDER BY START_VAL, NVL(END_VAL, 99)) THEN 1 ELSE 0
END) FLAG2
FROM TBL)
WHERE FLAG1 = 0
OR FLAG2 = 0;
① ② ③ ④
정답 : ① 해설 : LAG 함수는 현재 읽혀진 데이터의 이전 값을, LEAD 함수는 이후 값을 알아내는 함수이다. 위의 SQL에서 각 레코드별 FLAG1, FLAG2의 값은 다음과 같으며, 메인 쿼리의 WHERE 절이 FLAG1 = 0 OR FLAG2 = 0이므로 1, 4, 5, 6번째의 행이 출력된다.
문제 55
Q. 아래 설명 중, ( ㄱ ), ( ㄴ ) 에 해당하는 내용을 작성하시오.
DBMS에 생성된 USER와 다양한 권한들 사이에서 중개 역할을 할 수 있도록 DBMS에서는 ROLE을 제공한다. 이러한 ROLE을 DBMS USER에게 부여하기 위해서는 ( ㄱ ) 명령을 사용하며, ROLE을 회수하기 위해서는 ( ㄴ ) 명령을 사용한다.
정답 : (ㄱ) : GRANT, (ㄴ) : REVOKE 해설 : GRANT 명령은 DBMS 사용자에게 권한을 부여할 때 사용하며, REVOKE 명령은 부여된 권한을 회수할 때 사용한다.
문제 56
Q. 다음 중 B_User가 아래의 작업을 수행할 수 있도록 권한을 부여하는 DCL로 가장 적절한 것은?
UPDATE A_User.TB_A
SET col1='AAA'
WHERE col2=3;
① GRANT SELECT, UPDATE TO B_User; ② REVOKE SELECT ON A_User.TB_A FROM B_User; ③ DENY UPDATE ON A_User.TB_A TO B_User; ④ GRANT SELECT, UPDATE ON A_User.TB_A TO B_User;
정답 : ④ 해설 : 권한을 부여하는 명령어는 GRANT이며, WHERE 조건의 데이터를 찾기 위한 SELECT 권한과 데이터 변경을 위한 UPDATE 권한이 필요하다.
문제 57
Q. 아래의 ( ㄱ ) 에 들어갈 내용을 쓰시오.
DBMS에 사용자를 생성하면 기본적으로 많은 권한을 부여해야 한다. 많은 DBMS에서는 DBMS 관리자가 사용자별로 권한을 관리해야 하는 부담과 복잡함을 줄이기 위하여 다양한 권한을 그룹으로 묶어 관리할 수 있도록 사용자와 권한 사이에서 중개 역할을 수행하는 ( ㄱ ) 을 제공한다.
정답 : ROLE 해설 : ROLE 은 많은 DBMS 사용자에게 개별적으로 많은 권한을 부여하는 번거로움과 어려움을 해소하기 위해 다양한 권한을 하나의 그룹으로 묶어놓은 권한의 그룹이다.
문제 58
Q. 사용자 Lee가 릴레이션 R을 생성한 후, 아래와 같은 권한 부여 SQL문들을 실행하였다. 그 이후에 기능이 실행 가능한 SQL을 2개 고르시오. (단, A, B의 데이터 타입은 정수형이다.)
Lee: GRANT SELECT, INSERT, DELETE ON R TO Kim WITH GRANT OPTION;
Kim: GRANT SELECT, INSERT, DELETE ON R TO Park;
Lee: REVOKE DELETE ON R FROM Kim;
Lee: REVOKE INSERT ON R FROM Kim CASCADE;
① Park: SELECT * FROM R WHERE A = 400; ② Park: INSERT INTO R VALUES(400, 600); ③ Park: DELETE FROM R WHERE B = 800; ④ Kim : INSERT INTO R VALUES(500, 600);
정답 : ①, ③ 해설 : ① Kim에게 테이블 R에 SELECT, INSERT, DELETE 권한을 주면서 Kim이 다른 유저에게 테이블 R에 동일한 권한을 줄 수 있다. ③ Kim에게서 테이블 R의 DELETE 권한을 취소한다.
문제 59
Q. 다음 중 PL/SQL에 대한 설명으로 가장 부적절한 것은?
① 변수와 상수 등을 사용하여 일반 SQL 문장을 실행할 때 WHERE절의 조건 등으로 대입할 수 있다. ② Procedure, User Defined Function, Trigger 객체를 PL/SQL로 작성할 수 있다. ③ PL/SQL로 작성된 Procedure, User Defined Function은 전체가 하나의 트랜젝션으로 처리되어야 한다. ④ Procedure 내부에 작성된 절차적 코드는 PL/SQL엔진이 처리하고 일반적인 SQL 문장은 SQL실행기가 처리한다.
정답 : ③ 해설 : PL/SQL로 작성된 Procedure, User Defined Function은 작성자의 기준으로 트랜잭션을 분할할 수 있으며, 또한 프로시저 내에서 다른 프로시저를 호출할 경우에 호출 프로시저의 트랜잭션과는 별도로 PRAGMA AUTONOMOUS_TRANSACTION을 선언하여 자율 트랜잭션 처리를 할 수 있다.
문제 60
Q. 아래는 임시부서(TMP_DEPT) 테이블로부터 부서(DEPT) 테이블에 데이터를 입력하는 PL/SQL이다. 부서 테이블에 데이터를 입력하기 전에 부서 테이블의 모든 데이터를 ROLLBACK이 불가능 하도록 삭제하려고 한다. 다음 중 ( ㄱ ) 에 들어갈 내용으로 옳은 것은?
[PL/SQL]
create or replace procedure insert_dept authid current_user as
begin
( ㄱ )
INSERT /* + APPEND */ INTO DEPT (DEDPTNO, DNAME, LOC)
SELECT DEPTNO, DNAME, LOC
FROM TMP_DEPT;
commit;
end;
/
① TRUNCATE TABLE DEPT; ② DELETE FROM DEPT; ③ execute immediate 'TRUNCATE TABLE DEPT;' ④ execute 'TRUNCATE TABLE DEPT';
정답 : ③ 해설 : PL/SQL에서는 동적 SQL 또는 DDL 문장을 실행할 때 EXECUTE IMMEDIATE를 사용해야 한다. ②번은 ROLLBACK이 가능하도록 삭제하는 것이 아니므로 옳은 답이 아니다.
문제 61
Q. 다음 중 절차형 SQL 모듈에 대한 설명으로 가장 부적절한 것은?
① 저장형 프로시저는 SQL을 로직과 함께 데이터베이스 내에 저장해 놓은 명령문의 집합을 의미한다. ② 저장형 함수(사용자 정의 함수)는 단독적으로 실행되기 보다는 다른 SQL문을 통하여 호출되고 그 결과를 리턴하는 SQL의 보조적인 역할을 한다. ③ 트리거는 특정한 테이블에 INSERT, UPDATE, DELETE와 같은 DML문이 수행되었을 때 데이터베이스에서 자동으로 동작하도록 작성된 프로그램이다. ④ 데이터의 무결성과 일관성을 위해서 사용자 정의 함수를 사용한다.
정답 : ④ 해설 : Stored Module(ex: PL/SQL, LP/SQL, T-SQL)로 구현 가능한 기능은 ①, ②, ③ 세 가지이며, ④ 데이터의 무결성과 일관성을 위해 사용자 정의 함수를 사용하는 것은 트리거의 용도이다.
문제 62
Q. 다음 중 Trigger에 대한 설명으로 가장 부적절한 것은?
① Trigger는 데이터베이스에 의해서 자동으로 호출되고 수행된다. ② Trigger는 특정 테이블에 대해서 INSERT, UPDATE, DELETE 문이 수행되었을 때 호출되도록 정의할 수 있다. ③ Trigger는 TCL을 이용하여 트랜잭션을 제어할 수 있다. ④ Trigger는 데이터베이스에 로그인하는 작업에도 정의할 수 있다.
정답 : ③ 해설 : Trigger는 Procedure와 달리 Commit 및 Rollback 과 같은 TCL을 사용할 수 없다.
문제 63
Q. 다음 중 특정한 테이블에 INSERT, UPDATE, DELETE와 같은 DML문이 수행되었을 때, 데이터베이스에서 자동으로 동작하도록 작성된 저장 프로그램으로 가장 적절한 것은? (단, 사용자가 직접 호출하여 사용하는 것이 아니고 데이터베이스에서 자동적으로 수행하게 된다.)
① PROCEDURE ② USER DEFINED FUNCTION ③ PACKAGE ④ TRIGGER
정답 : ④ 해설 : Trigger는 테이블과 뷰, 데이터베이스 작업을 대상으로 정의할 수 있으며, 전체 트랜잭션 작업에 대해 발생되는 Trigger와 각 행에 대해서 발생되는 Trigger가 있다.