Q. 데이터베이스를 정의하고 접근하기 위해서는 데이터베이스 관리 시스템과의 통신 수단이 필요한데 이를 데이터 언어(Data Language)라고 하며, 그 기능과 사용 목적에 따라 데이터 정의어(DDL), 데이터 조작어(DML), 데이터 제어어(DCL)로 구분된다. 다음 중 데이터 언어와 SQL 명령어에 대한 설명으로 가장 부적절한 것은?
① 비절차적 데이터 조작어(DML)는 사용자가 무슨 데이터를 원하며, 어떻게 그것을 접근해야 되는지를 명세하는 언어이다. ② DML은 데이터베이스 사용자가 응용 프로그램이나 질의어를 통하여 저장된 데이터베이스를 실질적으로 접근하는데 사용되며 SELECT, INSERT, DELETE, UPDATE 등이 있다. ③ DDL은 스키마, 도메인, 테이블, 뷰, 인덱스를 정의하거나 변경 또는 제거할 때 사용되며 CREATE, ALTER, DROP, RENAME 등이 있다. ④ 호스트 프로그램 속에 삽입되어 사용되는 DML 명령어들을 데이터 부속어(Data Sub Language)라고 한다.
정답 : ①
해설 : 비절차적 데이터 조작어(DML)는 사용자가 무슨(What) 데이터를 원하는 지만을 명세한다. 하지만 절차적 데이터 조작어(DML)는 어떻게(How) 데이터를 접근해야 하는지 명세한다. (절차적 데이터 조작어로는 PL/SQL(오라클), T-SQL(SQL Server) 등이 있다.)
문제 5
Q. 다음 중 데이터베이스 시스템 언어의 종류와 해당하는 명령어를 바르게 연결한 것을 2개 고르시오.
① DML - SELECT ② TCL - COMMIT ③ DCL - DROP ④ DML - ALTER
정답 : ①, ②
해설 :
- DDL : 크알드트리
- DML : 세인업데
- DCL : 그래
- TCL : 커롤체
문제 6
Q. 다음 중 아래의 데이터 모델과 같은 테이블 및 PK 제약조건을 생성하는 DDL 문장으로 올바른 것은? (단, DBMS는 Oracle을 기준으로 한다.)
① CREATE TABLE PRODUCT ( PROD_ID VARCHAR2(10) NOT NULL ,PROD_NM VARCHAR2(100) NOT NULL ,REG_DT DATE NOT NULL ,REGR_NO NUMBER(10) NULL ); ALTER TABLE PRODUCT AND PRIMARY KEY PRODUCT_PK ON (PROD_ID); ② CREATE TABLE PRODUCT ( PROD_ID VARCHAR2(10) ,PROD_NM VARCHAR2(100) ,REG_DT DATE ,REG_NO NUMBER(10) ); ALTER TABLE PRODUCT ADD CONSTRAINT PRODUCT_PK PRIMARY KEY (PROD_ID); ③ CREATE TABLE PRODUCT ( PROD_ID VARCHAR2(10) NOT NULL ,PROD_NM VARCHAR2(100) NOT NULL ,REG_DT DATE NOT NULL ,REGR_NO NUMBER(10) NULL ,ADD CONSTRAINT PRIMARY KEY (PROD_ID) ); ④ CREATE TABLE PRODUCT ( PROD_ID VARCHAR2(10) NOT NULL ,PROD_NM VARCHAR2(100) NOT NULL ,REG_DT DATE NOT NULL ,REGR_NO NUMBER(10) ,CONSTRAINT PRODUCT_PK PRIMARY KEY (PROD_ID) );
①은 PK를 지정하는 ALTER TABLE 문장에 문법 오류가 존재하고, 올바른 문법이 사용된 문장은 다음과 같다. => @ALTER TABLE PRODUCT ADD CONSTRAINT PRODUCT_PK PRIMARY KEY (PROD_ID);@ ②는 NOT NULL 칼럼에 대해서 NOT NULL 제약조건을 지정하지 않았다. ③은 테이블을 생성할 때 PK를 지정하는 문장에 문법 오류가 존재한다.
문제 7
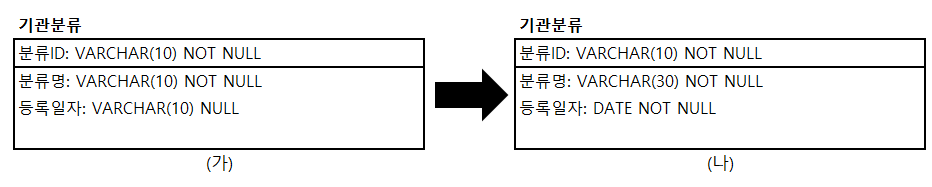
Q. 아래와 같이 데이터가 들어있지 않은 왼쪽 기관 분류 테이블 (가)를 오른쪽 기관 분류 테이블 (나)처럼 변경하고자 할 때 다음 중 올바른 SQL 문장은? (단, DBMS는 SQL Server로 가정한다.)
① ALTER TABLE 기관분류 ALTER COLUMN (분류명 VARCHAR(30), 등록일자 DATE NOT NULL); ② ALTER TABLE 기관분류 ALTER COLUMN (분류명 VARCHAR(30) NOT NULL, 등록일자 DATE NOT NULL); ③ALTER TABLE 기관분류 ALTER COLUMN 분류명 VARCHAR(30); ALTER TABLE 기관분류 ALTER COLUMN 등록일자 DATE NOT NULL; ④ALTER TABLE 기관분류 ALTER COLUMN 분류명 VARCHAR(30) NOT NULL; ALTER TABLE 기관분류 ALTER COLUMN 등록일자 DATE NOT NULL;
정답 : ④
해설 :
①, ② SQL Server에서는 여러개의 칼럼을 동시에 수정하는 구문은 지원하지 않으므로 오류가 발생한다. 또한 SQL Server 에서는 괄호를 사용하지 않는다.
③ 분류명을 수정할 때 NOT NULL 구문을 지정하지 않으면, 기존의 NOT NULL 제약조건이 NULL로 변경되므로 NOT NULL 요건을 만족하지 않는다.
문제 8
Q. 다음 중 NULL의 설명으로 가장 부적절한 것은?
① 모르는 값을 의미한다. ② 값의 부재를 의미한다. ③ 공백 문자(Empty String) 혹은 숫자 0을 의미한다. ④ NULL과 모든 비교(IS NULL 제외)는 알 수 없음(Unknown)을 반환한다.
정답 : ③
해설 : NULL은 아스키 코드 0번이며, 공백(아스키 코드 32번)이나 숫자 0(아스키 코드 48번)과는 전혀 다른 값이다. 또한 조건에 맞는 데이터가 없을 때의 공집합과도 다르다. 아직 정의되지 않은 미지의 값이며, 현재 데이터를 입력하지 못하는 경우를 의미한다. NULL과 산술 연산을 수행할 경우 그 결과는 항상 NULL이다.
문제 9
Q. 아래 테이블 T, S, R이 각각 다음과 같이 선언되었다. 다음 중 DELETE FROM T; 를 수행한 후에 테이블 R에 남아있는 데이터로 가장 적절한 것은?
CREATE TABLE T
(C INTEGER PRIMARY KEY,
D INTEGER);
CREATE TABLE S
(B INTEGER PRIMARY KEY,
C INTEGER REFERENCES T(C) ON DELETE CASCADE);
CREATE TABLE R
(A INTEGER PRIMARY KEY,
B INTEGER REFERENCES S(B) ON DELETE SET NULL);
현재 테이블 T, S, R의 상태는 다음과 같다.
① (1, NULL)과 (2, 2) ② (1, NULL)과 (2, NULL) ③ (2, 2) ④ (1, 1)
정답 : ②
해설 : @DELETE FROM T;@ 명령 수행 후, T 테이블은 두 건 모두 삭제 된다. S 테이블에는 CASCADE 옵션이 적용되어 있으므로 두 건 모두 삭제된다. R 테이블에는 SET NULL 옵션이 적용되어 있으므로 자식 필드에 해당하는 B 칼럼의 값이 NULL로 변경된다.
문제 10
Q. 다음 중 테이블 생성시 칼럼별 생성할 수 있는 제약조건(Constraints)에 대한 설명으로 가장 부적절한 것은?
① UNIQUE : 테이블 내에서 중복되는 값이 없으며 NULL 입력이 불가능하다. ② PK : 주키로 테이블당 1개만 생성이 가능하다. ③ FK : 외래키로 테이블당 여러 개 생성이 가능하다. ④ NOT NULL : 명시적으로 NULL 입력을 방지한다.
정답 : ①
해설 : UNIQUE는 테이블 내에서 중복되는 값이 없지만, NULL 입력이 가능하다.
문제 11
Q. 다음 중 물리적 테이블 명으로 가장 적절한 것은?
① EMP_10 ② 100-EMP ③ EMP-100 ④ 100_EMP
정답 : ①
해설 : 테이블 생성 시 주의사항은 다음과 같다.
- 테이블명온 객체를 의미할 수 있는 적정한 이름을 사용한다. 가능한 단수형을 권고한다. - 테이블명은 다른 테이블의 이름과 중복되지 않아야 한다. - 한 테이블 내에서는 칼럼명이 중복되게 지정할 수 없다. - 테이블 이름을 지정하고 각 칼럼들은 괄호 "( )" 로 묶어 지정한다. - 각 칼럼들은 콤마 "," 로 구분되고. 테이블 생성문의 끝은 항상 세미콜론 ";" 으로 끝난다. - 칼럼에 대해서는 다른 테이블까지 고려하여 데이터베이스 내에서는 일관성 있게 사용하는 것이 좋다. (데이터 표준화 관점) - 칼럼 뒤에 데이터 유형은 꼭 지정되어야 한다. - 테이블명과 칼럼명은 반드시 문자로 시작해야 하고, 벤더별로 길이에 대한 한계가 있다. - 벤더에서 사전에 정의한 예약어(Reserved Word)는 쓸 수 없다. - A-Z, a-z, 0-9, _, $, # 문자만 허용된다.
문제 12
Q. 아래와 같은 테이블 구조를 정의하려고 한다. 이때 아직 부서가 정의되지 않은 사원은 기본부서(코드 : '0000')로 배치하고, 입사일자(JOIN_date) 기준으로 많은 조회가 발생하므로 입사일자에 INDEX를 생성하려고 한다. 다음 중 올바른 SQL 문장을 2개 고르시오.
① CREATE TABLE EMP (EMP_NO VARCHAR2(10) PRIMARY KEY, EMP_NM VARCHAR2(30) NOT NULL, DEPT_CODE VARCHAR2(4) DEFAULT '0000' NOT NULL, JOIN_DATE DATE NOT NULL, REGIST_DATE DATE NULL ); CREATE INDEX IDX_EMP_01 ON EMP (JOIN_DATE); ②CREATE TABLE EMP (EMP_NO VARCHAR2(10) PRIMARY KEY, EMP_NM VARCHAR2(30) NOT NULL, DEPT_CODE VARCHAR2(4) DEFAULT '0000', JOIN_DATE DATE NOT NULL, REGIST_DATE DATE ); CREATE INDEX IDX_EMP_01 ON EMP (JOIN_DATE); ③CREATE TABLE EMP (EMP_NO VARCHAR2(10) NOT NULL, EMP_NM VARCHAR2(30) NOT NULL, DEPT_CODE VARCHAR2(4) DEFAULT '0000' NOT NULL, JOIN_DATE DATE NOT NULL, REGIST_DATE DATE ); ALTER TABLE EMP ADD CONSTRAINT EMP_PK PRIMARY KEY (EMP_NO); CREATE INDEX IDX_EMP_01 ON EMP (JOIN_DATE); ④CREATE TABLE EMP (EMP_NO VARCHAR2(10) NOT NULL PRIMARY KEY, EMP_NM VARCHAR2(30) NOT NULL, DEPT_CODE VARCHAR2(4) DEFAULT '0000' NOT NULL, JOIN_DATE DATE NOT NULL, REGIST_DATE DATE NULL ); ALTER TABLE EMP ADD CONSTRAINT EMP_PK PRIMARY KEY(EMP_NO); CREATE INDEX IDX_EMP_01 ON EMP (JOIN_DATE);
정답 : ①, ③
해설 :
② SQL 문장은 정상적으로 수행되지만, DEPT_CODE 칼럼에 NOT NULL 제약조건이 생성되지 않는다. NOT NULL 제약 조건이 생성되지 않으면 명시적으로 DEPT_CODE 칼럼에 NULL을 입력하게 되면 NULL이 입력되는 문제가 발생한다. ④ 테이블 생성문과 인덱스 생성문은 정상적으로 수행되지만, 테이블 생성문장에서 이미 PRIMARY KEY를 지정하였으므로 ALTER TABLE 문장에서 오류가 발생한다.
문제 13
Q. 다음 중 아래와 같은 문장으로 '학생' 테이블을 생성한 후, 유효한 튜플(Tuple)들을 삽입하였다. SQL 1, SQL 2 문장의 실행 결과로 가장 적절한 것은?
생성)
create table 학생 (학번 char(8) primary key, 장학금 integer);
SQL1: select count(*) from 학생 SQL2: select count(학번) from 학생
① SQL1, SQL2 문장의 실행 결과는 다를 수 있으며, 그 이유는 장학금 속성(Attribute)에 널(Null) 값이 존재할 수 있기 때문이다. ② SQL1, SQL2 문장의 실행 결과는 항상 다르다. ③ SQL1, SQL2 문장의 실행 결과는 항상 같다. ④ SQL1, SQL2 문장의 실행 결과는 다를 수 있으며, 그 이유는 학번 속성(Attribute)에 널(Null) 값이 존재할 수 있기 때문이다.
정답 : ③
해설 : 학번 칼럼이 PK이기 때문에 NULL 값이 없다. (PK는 NULL 값이 없다.) 따라서 count(*)와 COUNT(학번)의 결과는 항상 같다.
문제 14
Q. 다음 외래키에 대한 설명으로 가장 부적절한 것을 2개 고르시오.
① 테이블 생성시 설정할 수 있다. ② 외래키 값은 널 값을 가질 수 없다. ③ 한 테이블에 하나만 존재해야 한다. ④ 외래키 값은 참조 무결성 제약을 받을 수 있다.
정답 : ②, ③
해설 : 외래키 값은 NULL 값을 가질 수 있으며, 한 테이블에 여러 개 존재할 수 있다.
문제 15
Q. 다음 중 데이터베이스 테이블의 제약조건(Constraint)에 대한 설명으로 가장 부적절한 것은?
① Check 제약조건(Constraint)은 데이터베이스에서 데이터의 무결성을 유지하기 위하여 테이블의 특정 칼럼(Column)에 설정하는 제약이다. ② 기본키 (Primary Key ) 는 반드시 테이블 당 하나의 제약만을 정의할 수 있다. ③ 고유키(Unique Key)로 지정된 모든 칼럼들은 Null 값을 가질 수 없다. ④ 외래키(Foreign Key)는 테이블간의 관계를 정의하기 위해 기본키(Primary Key)를 다른 테이블의 외래키가 참조하도록 생성한다.
정답 : ③
해설 : 고유키(Unique Key)로 지정된 모든 칼럼은 NULL 값을 가질 수도 있다.
문제 16
Q. 4개의 칼럼으로 이루어진 EMP 테이블에서 COMM 칼럼을 삭제하고자 할 때, 아래 SQL 문장의 ( ㄱ ), ( ㄴ ) 안에 들어갈 내용을 기술하시오.
( ㄱ ) TABLE EMP
( ㄴ ) COMM;
정답 : (ㄱ) ALTER, (ㄴ) : DROP COLUMN
해설 : @ALTER TABLE 테이블명 DROP COLUMN 칼럼명@ 과 같이 SQL을 작성하여 특정 테이블에서 특정 컬럼을 삭제할 수 있다.
문제 17
Q. 아래 7개의 SQL 문장이 성공적으로 수행되었다고 할 때, A, B, C 세 개의 SQL 문장을 차례대로 실행하면 A와 C의 SELECT 문장 수행 결과는 각각 무엇인가?
CREATE TABLE 부서 (부서번호 CHAR(10), 부서명 CHAR(10), PRIMARY KEY(부서번호));
CREATE TABLE 직원 (직원번호 CHAR(IO), 소속부서 CHAR(IO), PRIMARY KEY(직원번호),
FOREIGN KEY(소속부서) REFERENCES 부서(부서번호) ON DELETE CASCADE);
INSERT INTO 부서 VALUES('1O', '영업과');
INSERT INTO 부서 VALUES('2O', '기획과');
INSERT INTO 직원 VALUES('1000', '10');
INSERT INTO 직원 VALUES('2000', '20');
INSERT INTO 직원 VALUES('3000', '20');
COMMIT;
A. SELECT COUNT(직원번호) FROM 직원
B. DELETE FROM 부서 WHERE 부서번호 = '20';
C. SELECT COUNT(직원번호) FROM 직원
COMMIT;
① 3, null ② 3, 1 ③ 3, 2 ④ 3, 3
정답 : ②
해설 : @DELETE FROM 부서 WHERE 부서번호 = '20'@ 명령을 실행할 경우, CASCADE 참조 무결성 규정으로 인하여 직원 테이블의 '2000', '3000'도 같이 삭제된다. @SELECT COUNT(직원번호) FROM 직원@ 명령을 실행할 경우, 직원 테이블 '1000'에 대한 1건만 출력된다.
문제 18
Q. STADIUM 테이블의 이름을 STADIUM_JSC로 변경하는 SQL을 작성하시오. (ANSI 표준 기준)
정답 : RENAME STADIUM TO STADIUM_JSC;
해설 : 테이블 이름은 @RENAME 변경전이름 TO 변경후이름@ 명령을 이용하여 변경할 수 있다.
문제 19
Q. 표준 SQL(SQL:1999)에서 테이블 생성시 참조 관계를 정의하기 위해 외래키(Foreign Key)를 선언한다. 관계형 데이터베이스에서 Child Table의 FK 데이터 생성시 Parent Table에 PK가 없는 경우, Child Table 데이터 입력을 허용하지 않는 참조 동작(Referential Action)인 것은?
① CASCADE ② RESTRICT ③ AUTOMATIC ④ DEPENDENT
정답 : ④
해설 :
※ DELETE(/MODIFY) Action : CASCADE, SET NULL, SET DEFAULT, RESTRICT (부서→사원) (1)CASCADE : Master 삭제 시, Child 같이 삭제 (2) SET NULL : Master 삭제 시, Child 해당 필드 Null (3) SET DEFAULT : Master 삭제 시, Child 해당 필드 Default 값으로 설정 (4) RESTRICT : Child 테이블에 PK 값이 없는 경우만 Master 삭제 허용 (5) NO ACTION : 참조 무결성을 위반하는 삭제/수정 액션을 취하지 않음.
※ INSERT Action : AUTOMATIC, SET NULL, SET DEFAULT, DEPENDENT (부서→사원) (1) AUTOMATIC : Master 테이블에 PK가 없는 경우, Master PK를 생성한 후 Child 입력 (2) SET NULL : Master 테이블에 PK가 없는 경우, Child 외부키를 Null 값으로 처리 (3) SET DEFAULT : Master 테이블에 PK가 없는 경우, Child 외부키를 지정된 기본값으로 입력 (4) DEPENDENT : Master 테이블에 PK가 존재할 때만 Child 입력 허용 (5) NO ACTION : 참조 무결성을 위반하는 입력 액션을 취하지 않음.
문제 20
Q. 아래와 같은 SQL문에 대해 삽입이 성공하는 SQL문은?
CREATE TABLE TBL
(
ID NUMBER PRIMARY KEY,
AMT NUMBER NOT NULL,
DEGREE VARCHAR2(1)
)
1. INSERT INTO TBL VALUES(1, 100)
2. INSERT INTO TBL(ID, AMT, DEGREE) VALUES(2, 200, 'AB')
3. INSERT INTO TBL(ID, DEGREE) VALUES(4, 'X')
4. INSERT INTO TBL(ID, AMT) VALUES(3, 300)
5. INSERT INTO TBL VALUES(5, 500, NULL)
① 1, 2 ② 2, 3 ③ 3, 4 ④ 4, 5
정답 : ④
해설 :
① 삽입 칼럼을 명시하지 않았을 경우 모든 칼럼을 삽입해야 한다. ② DEGREE 칼럼의 길이는 VARCHAR2(1)이다. 'AB'는 칼럼 길이를 초과한다. ③ NOT NULL 칼럼인 AMT 칼럼을 명시하지 않았다.
문제 21
Q. 아래와 갈은 데이터 모델에서 데이터를 조작하려고 한다. 다음 중 오류가 발생하는 SQL 문장인 것은?
① INSERT INTO BOARD VALUES (1, 'Q&A', 'Y', SYSDATE, 'Q&A 게시판'); ② INSERT INTO BOARD (BOARD_ID, BOARD_NM, USE_YN, BOARD_DESC) VALUES ('100', 'FAQ', 'Y', 'FAQ 게시판'); ③ UPDATE BOARD SET USE_YN = 'N' WHERE BOARD_ID = '1'; ④ UPDATE BOARD SET BOARD_ID = 200 WHERE BOARD_ID = '100';
정답 : ②
해설 : REG_DATE 칼럼에 NOT NULL 제약 조건이 있지만, INSERT INTO 구문에는 REG_DATE 칼럼이 대입되지 않아 NULL이 입력되므로 오류가 발생한다.
문제 22
Q. 아래 데이터 모델과 같이 고객과 주문 테이블이 생성되어 있으며, 고객과 주문 테이블에 입력되어 있는 데이터는 아래 표와 같다. 이 때 FK_001 이라는 제약조건을아래 SQL과 같이 설정하였다. 다음 중 오류 없이 정상적으로 수행되는 SQL을 2개 고르시오.
[SQL]
ALTER TABLE 주문 ADD CONSTRAINT FK_001 FOREIGN KEY (고객ID)
REFERENCES 고객 (고객ID) ON DELETE SET NULL;
① INSERT INTO 고객 VALUES ('C003', '강감찬', '2014-01-01'); ② INSERT INTO 주문 VALUES ('0005', 'C003', '2013-12-28'); ③ DELETE FROM 주문 WHERE 주문번호 IN ('0001', '0002'); ④ DELETE FROM 고객 WHERE 고객ID = 'C002';
정답 : ①, ③
해설 :
② 고객 테이블에 존재하지 않는 고객ID(C003)의 주문을 입력하라고 하여 무결성 제약 오류 발생 (①번 SQL 수행 후에는 정상 작동) ④ 고객 테이블의 고객ID 'C002'를 삭제하려고 할 때 SQL에 의해 추가된 CONSTRAINT에 따라 주문 테이블의 고객ID를 NULL로 업데이트하려고 DBMS에서 시도하지만, 주문 테이블 고객ID 컬럼의 NOT NULL 제약조건에 의해 실패한다.
문제 23
Q. 개발 프로젝트의 표준은 모든 삭제 데이터에 대한 로그를 남기는 것을 원칙으로 하고, 테이블 삭제의 경우는 허가된 인력만이 정기적으로 수행 가능하도록 정하고 있다. 개발팀에서 사용 용도가 없다고 판단한 STADIUM 테이블의 데이터를 삭제하는 가장 좋은 방법은 무엇인가?
① DELETE FROM STADIUM; ② DELETE * FROM STADIUM; ③ TRUNCATE TABLE STADIUM; ④ DROP TABLE STADIUM;
정답 : ①
해설 : TRUNCATE TABLE과 DROP TABLE은 로그를 남기지 않으므로 개발 기준과 맞지 않다. DELETE는 로그를 남기므로 개발 기준에 부합한다. 따라서 ①이 정답이다. (②는 문법에 맞지 않다.)
문제 24
Q. 아래의 고객지역 테이블을 대상으로 질의 결과와 같이 거주지와 근무지를 출력하고자 한다. 아래 SQL의 ( ㄱ ) 안에 들어갈 내용을 작성하시오.
[SQL]
SELECT ( ㄱ ) 거주지, 근무지
FROM 고객지역;
정답 : DISTINCT
해설 : 데이터의 중복을 제거하는 명령어는 DISTINCT이다. GROUP BY 문을 사용하여 다음과 같이 중복 데이터를 제거할 수도 있다.
SELECT 거주지, 근무지
FROM 고객지역
GROUP BY 거주지, 근무지;
문제 25
Q. 다음 중 아래와 같은 상황에서 사용할 수 있는 SQL 명령어는?
우리가 관리하는 데이터베이스의 "매출" 테이블이 너무나 많은 디스크 용량을 차지하여 "매출" 테이블에서 필요한 데이터만을 추출하여 별도의 테이블로 옮겨 놓았다. 이후 "매출" 원본 테이블의 데이터를 모두 삭제함과 동시에, 디스크 사용량도 초기화 하고자 한다. (단, "매출' 테이블의 스키마 정의는 유지한다.)
① TRUNCATE TABLE 매출; ② DELETE FROM 매출; ③ DROP TABLE 매출; ④ DELETE TABLE FROM 매출;
정답 : ①
해설 : 특정 테이블의 모든 데이터를 삭제하고, 디스크 사용량을 초기화하기 위해서는 TRUNCATE TABLE 명령을 사용해야 한다.
문제 26
Q. 다음 중 DELETE와 TRUNCATE, DROP 명령어에 대해 비교한 설명으로 가장 부적절한 것을 2개 고르시오.
① 특정 테이블에 대하여 WHERE 조건절이 없는 DELETE 명령을 수행하면 DROP TABLE 명령을 수행했을 때와 똑같은 결과를 얻올 수 있다. ② DROP 명령어는 테이블 정의 자체를 삭제하고, TRUNCATE 명령어는테이블을 초기 상태로 만든다. ③ TRUNCATE 명령어는 UNDO를 위한 데이터를 생성하지 않기 때문에동일 데이터량 삭제시 DELETE보다 빠르다. ④ DROP은 Auto Commit이 되고, DELETE와 TRUNCATE는 사용자Commit으로 수행된다.
정답 : ①, ④
해설 : DROP, TRUNCATE는 Auto Commit이 되고, DELETE는 사용자 Commit으로 수행된다.
DROP
TRUNCATE
DELETE
DDL
DDL (일부 DML 성격 가짐.)
DML
ROLLBACK 불가능
ROLLBACK 불가능
COMMIT 이전 ROLLBACK 가능
AUTO COMMIT
AUTO COMMIT
사용자 COMMIT
테이블이 사용했던 Storage를 모두 Release
테이블이 사용했던 Storage 중 최초 테이블 생성시 할당된 Storage만 남기고 Release
데이터를 모두 Delete 해도 사용했던 Storage는 Relase 되지 않음.
테이블의 정의 자체를 완전히 삭제함.
테이블을 최초 생성된 초기 상태로 만듦.
데이터만 삭제
문제 27
Q. 데이터베이스 트랜잭션에 대한 설명으로 가장 부적절한 것을 2개 고르시오.
① 원자성(atomicity) : 트랜잭션에서 정의된 연산들은 모두 성공적으로 실행되던지 아니면 전혀 실행되지 않은 상태로 남아 있어야 한다. ② 일관성(consistency) : 트랜잭션이 성공적으로 수행되면 그 트랜잭션이 갱신한 데이터베이스의 내용은 영구적으로 저장된다. ③ 고립성(isolation) : 트랜잭션이 실행와는 도중에 다른 트랜잭션의 영향올 받아 잘못된 결과를 만들어서는 안된다. ④ 지속성(durability) : 트랜잭션이 실행되기 전의 데이터베이스 내용이 잘못 되어 있지 않다면 트랜잭션이 실행된 이후에도 데이터베이스의 내용에 잘못이 있으면 안된다.
정답 : ②, ④
해설 : 데이터베이스 트랜잭션의 특성으로는 ACID(원자성, 일관성, 고립성, 지속성)이 있다. 이 문제에서는 일관성과 지속성의 설명이 바뀌었다.
특성
설명
원자성 (Atomicity)
트랜잭션에서 정의된 연산들은 모두 성공적으로 실행되던지 아니면 전혀 실행되지 않은 상태로 남아 있어야 한다. (All or Nothing)
일관성 (Consistency)
트랜잭션이 실행되기 전의 데이터베이스 내용이 잘못 되어 있지 않다면 트랜잭션이 실행된 이후에도 데이터베이스의 내용에 잘못이 있으면 안된다.
고립성 (Isolation)
트랜잭션이 실행와는 도중에 다른 트랜잭션의 영향올 받아 잘못된 결과를 만들어서는 안된다.
지속성 (Durability)
트랜잭션이 성공적으로 수행되면 그 트랜잭션이 갱신한 데이터베이스의 내용은 영구적으로 저장된다.
문제 28
Q. 데이터베이스의 트랜잭션에 대한 격리성이 낮은 경우 발생할 수 있는 문제점으로 가장 부적절한 것을 2개 고르시오.
① Dirty Read : 다른 트랜잭션에 의해 수정되었고, 이미 커밋된 데이터를 읽는 것을 말한다. ② Non-Repeatable Read : 한 트랜잭션 내에서 같은 쿼리를 두 번 수행했는데, 그 사이에 다른 트랜잭션이 값을 수정 또는 삭제하는 바람에 두 쿼리 결과가 다르게 나타나는 현상을 말한다. ③ Phantom Read : 한 트랜잭션 내에서 같은 쿼리를 두 번 수행했는데, 첫번째 쿼리에서 없던 유렁 레코드가 두 번째 쿼리에서 나타나는 현상을 말한다. ④ Isolation : 트랜잭션이 실행되는 도중에 다른 트랜잭션의 영향을 받아 잘못된 결과를 만들어서는 안된다.
정답 : ①, ④
해설 : Dirty Read란, 다른 트랜잭션에 의해 수정되었지만, 아직 커밋되지 않은 데이터를 읽는 것을 의미한다. Isolation은 트랜잭션이 실행되는 도중에 다른 트랜잭션의 영향을 받아 잘못된 결과를 만들어서는 안된다는 것을 의미한다. 하지만 이것은 트랜잭션의 4가지 특성으로 문제점은 아니고, 목표라고 할 수 있다.
문제 29
Q. 테이블 A에 대해 아래와 같은 SQL을 수행하였을 때 테이블 A의 ID '001'에 해당하는 최종 VAL의 값이 ORACLE에서는 200, SQL Server에서는 100이 되었다. 다음 설명 중 가장 부적절한 것은? (단, AUTO COMMIT은 FALSE로 설정되어 있다.)
[SQL]
UPDATE A SET VAL = 200 WHERE ID = '001';
CREATE TABLE B (ID CHAR(3) PRIMARY KEY);
ROLLBACK;
① ORACLE에서는 CREATE TABLE 문장을 수행한 후, 묵시적으로 COMMIT이 수행되어 VAL 값은 200이 되었다. ② SQL Server에서는 ROLLBACK 문장에 의해 UPDATE가 취소되어 VAL 값은 100이 되었다. ③ ORACLE에서는 CREATE TABLE 문장 수행에 의해 VAL 값은 200이 되었지만, ROLLBACK 실행으로 인하여 최종적으로 B 테이블은 생성되지 않았다. ④ SQL Server에서는 ROLLBACK 실행으로 인하여 UPDATE가 취소되었으며, 최종적으로 B 테이블은 생성되지 않았다.
정답 : ③
해설 : Oracle에서 DDL 문장(CREATE)의 수행은 내부적으로 트랜잭션을 종료(Auto Commit)시키므로, B 테이블은 생성된다. SQL Server는 DDL 문장을 수행하더라도 Auto Commit을 수행하지 않는다.
문제 30
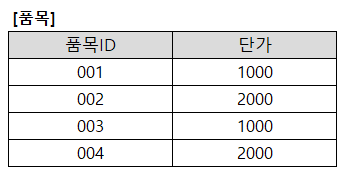
Q. 아래 내용의 ( ㄱ ), ( ㄴ ), ( ㄷ ) 에 해당하는 단어를 순서대로 작성하시오.
( ㄱ ) 은 데이터베이스의 논리적 연산단위로서 밀접히 관련되어 분리될 수 없는 한 개 이상의 데이터베이스 조작을 가리킨다. ( ㄱ )의 종료를 위한 대표적 명령어로서는 데이터에 대한 변경사항을 데이터베이스에 영구적으로 반영하는 ( ㄴ )과 데이터에 대한 변경사항을 모두 폐기하고 변경 전의 상태로 되돌리는 ( ㄷ )이 있다.
BEGIN TRANSACTION
INSERT INTO 품목(품목ID, 단가) VALUES('005', 2OOO)
COMMIT
BEGIN TRANSACTION
DELETE 품목 WHERE 품목ID='002'
BEGIN TRANSACTION
UPDATE 품목 SET 단가=2000 WHERE 단가=1000
ROLLBACK
SELECT COUNT(품목ID) FROM 품목 WHERE 단가=2000
① 0 ② 2 ③ 3 ④ 4
정답 : ③
해설 : ROLLBACK 구문은 COMMIT 되지 않은 상위의 모든 트랜잭션을 모두 롤백한다. 따라서 ROLLBACK 수행 후, @INSERT INTO 품목(품목ID, 단가) VALUES('005', 2000)@ 명령이 수행 된 후, @SELECT COUNT(품목ID) FROM 품목 WHERE 단가=2000@ 명령이 수행된다.
문제 32
Q. 아래의 상품 테이블의 데이터에 대하여 관리자가 아래와 같이 SQL 문장을 실행하여 데이터를 변경하였다. 데이터 변경 후의 상품ID '001'의 최종 상품명을 작성하시오.
[SQL 구문]
BEGIN TRANSACTION;
SAVE TRANSACTION SP1;
UPDATE 상품 SET 상품명 = 'LCD-TV' WHERE 상품ID = '001';
SAVE TRANSACTION SP2;
UPDATE 상품 SET 상품명 = '평면-TV' WHERE 상품ID = '001';
ROLLBACK TRANSACTION SP2;
COMMIT;
정답 : LCD-TV
문제 33
Q. 아래의 ( ㄱ ) 에 들어갈 내용을 적으시오.
SQL을 사용하여 데이터베이스에서 데이터를 조회할 때 원하는 데이터만을 검색하기 위해서 SELECT, FROM 절과 함께 ( ㄱ ) 을(를) 이용하여 조회되는 데이터의 조건을 설정하여 데이터를 제한할 수 있다.
정답 : WHERE 또는 WHERE 절
문제 34
Q. 다음 중 SQL의 실행 결과로 가장 적절한 것은?
[SQL 구문]
SELECT COUNT(*)
FROM EMP_TBL
WHERE EMPNO > 100 AND SAL >= 3000 OR EMPNO = 200;
① 0 ② 1 ③ 2 ④ 3
정답 : ②
해설 : 논리 연산자의 우선 순위는 NOT > AND > OR 순이다. 따라서 위의 명령을 실행했을 경우, (200, 3000)인 인스턴스만 조회된다.
문제 35
Q. 다음 중 SELECT COL1 + COL3 FROM TAB_A; 의 결과로 가장 적절한 것은?
① NULL ② 80 10 60 ③ 150 ④ 50 NULL NULL
정답 : ④
해설 : NULL 값이 포함된 사칙 연산의 결과는 NULL이다.
30 + 20 = 50
NULL + 40 = NULL
50 + NULL = NULL
문제 36
Q. 다음 SQL 문장 중 COLUMN1의 값이 널(NULL)이 아닌 경우를 찾아내는 문장으로 가장 적절한 것은? (ANSI 표준 기준)
① SELECT * FROM MYTABLE WHERE COLUMN1 IS NOT NULL ②SELECT * FROM MYTABLE WHERE COLUMN1 <> NULL ③ SELECT * FROM MYTABLE WHERE COLUMN1 != NULL ④ SELECT * FROM MYTABLE WHERE COLUMN1 NOT NULL
정답 : ①
해설 : NULL 값을 조건절(WHERE)에서 사용하는 경우 IS NULL, IS NOT NULL이라는 키워드를 사용해야 한다.
문제 37
Q. 아래와 같은 DDL 문장으로 테이블을 생성하고, SQL들을 수행했을 때 다음 설명 중 옳은 것은?
CREATE TABLE 서비스
(
서비스번호 VARCHAR2(10) PRIMARY KEY,
서비스명 VARCHAR2(100) NULL,
개시일자 DATE NOT NULL
);
[SQL]
(ㄱ) SELECT * FROM 서비스 WHERE 서비스번호 = 1;
(ㄴ) INSERT INTO 서비스 VALUES ('999', '', '2015-11-11');
(ㄷ) SELECT * FROM 서비스 WHERE 서비스명 = '';
(ㄹ) SELECT * FROM 서비스 WHERE 서비스명 IS NULL;
① 서비스번호 칼럼에 모든 레코드 중에서 ‘001’과 같은 숫자 형식으로 하나의 레코드만이라도 입력되어 (ㄱ)은 오류 없이 실행된다. ② ORACLE에서 (ㄴ)과 같이 데이터를 입력하였을 때. 서비스명 칼럼에 공백문자 데이터가 입력된다. ③ ORACLE에서 (ㄴ)과 같이 데이터를 입력하고, ㄷ)과 같이 조회하였을 때, 데이터는 조회된다. ④ SQL Server에서 (ㄴ)과같이 데이터를 입력하고, (ㄹ)과 같이 조회하였을 때, 데이터는 조회되지 않는다.
정답 : ④
해설 : (ㄴ)과 같이 데이터가 입력되어 있을 때, SQL Server에서 데이터를 조회하려면 서비스명 = ''로 조회해야 한다. Oracle은 공백 문자 입력 시 NULL이 삽입되지만, SQL Server에서는 공백 문자 입력 시 공백 문자가 삽입된다. 따라서 SQL Server에서는 @서비스명 = ''@ 로 조회해야 한다.
문제 38
Q. 아래와 같이 월별매출 테이블에 데이터가 입력되어 있다. 다음 중 2014년 11월부터 2015년 03월까지의 매출금액 합계를 출력하는 SQL 문장으로 옳은 것은?
①
SELECT SUM(매출금액) AS 매출금액합계
FROM 월별매출
WHERE 년 BETWEEN '2014' AND '2015'
AND 월 BETWEEN '03' AND '12';
②
SELECT SUM(매출금액) AS 매출금액합계
FROM 월별매출
WHERE 년 IN ('2014', '2015')
AND 월 IN ('11', '12', '03', '04', '05');
③
SELECT SUM(매출금액) AS 매출금액합계
FROM 월별매출
WHERE (년 = '2014' OR 년 = '2015')
AND (월 BETWEEN '01' AND '03' OR 월 BETWEEN '11' AND '12');
④
SELECT SUM(매출금액) AS 매출금액합계
FROM 월별매출
WHERE 년 = '2014' AND 월 BETWEEN '11' AND '12'
OR 년 = '2015' AND 월 BETWEEN '01' AND '03';
정답 : ④
해설 :
①의 조건은 2014년 03월부터 12월까지 매출금액과 2015년 03월부터 2015년 12월까지의 매출금액의 합이다. ②의 조건은 ①의 조건과 동일하다. ③의 조건은 2014년 01월부터 12월까지의 매출금액과 2015년 01월부터 12월까지의 매출금액의 합이다. 즉, 전체 데이터의 합이다.
문제 39
Q. 아래 테이블 스키마를 참조하여 SQL 문장을 작성하였다. 다음 중 결과가 다른 SQL 문장은?
①
SELECT SVC_ID, COUNT(*) AS CNT
FROM SVC_JOIN
WHERE SVC_END_DATE >= TO_DATE('20150101000000', 'YYYYMMDDHH24MISS')
AND SVC_END_DATE <= TO_DATE('20150131235959', 'YYYYMMDDHH24MISS')
AND CONCAT(JOIN_YMD, JOIN_HH) = '2014120100'
GROUP BY SVC_ID;
②
SELECT SVC_ID, COUNT(*) AS CNT
FROM SVC_JOIN
WHERE SVC_END_DATE >= TO_DATE('20150101', 'YYYYMMDD')
AND SVC_END_DATE < TO_DATE('20150201', 'YYYYMMDD')
AND (JOIN_YMD, JOIN_HH) IN (('20141201', '00'))
GROUP BY SVC_ID;
③
SELECT SVC_ID, COUNT(*) AS CNT
FROM SVC_JOIN
WHERE '201501' = TO_CHAR(SVC_END_DATE, 'YYYYMM')
AND JOIN_YMD = '20141201'
AND JOIN_HH = '00'
GROUP BY SVC_ID;
④
SELECT SVC_ID, COUNT(*) AS CNT
FROM SVC_JOIN
WHERE TO_DATE('201501', 'YYYYMM') = SVC_END_DATE
AND JOIN_YMD || JOIN_HH = '2014120100'
GROUP BY SVC_ID
정답 : ④
해설 : ①, ②, ③번 SQL은 모두 가입이 2014년 12월 01일 00시에 발생했고, 서비스 종료일시가 2015년 01월 01일 00시 00분 00초와 2015년 01월 01일 23시 59분 59초 사이에 만료되는 데이터를 찾는 조건이지만, ④번 SQL은 가입 조건은 동일하지만, 서비스 종료 일시가 2015년 01월 01일 00시 00분 00초에 종료되는 SQL을 찾는 조건이다.
문제 40
Q. 아래와 같은 내장 함수에 대한 설명 중에서 옳은 것을 모두 묶은 것은?
가) 함수의 입력 행수에 따라 단일행 함수와 다중행 함수로 구분할 수 있다. 나) 단일행 함수는 SELECT, WHERE, ORDER BY, UPDATE의 SET절에 사용이 가능하다. 다) 1:M 관계의 두 테이블을 조인할 경우 M쪽에 다중행이 출력되므로 단일행 함수는 사용할 수 없다. 라) 단일행 함수는 다중행 함수와 다르게 여러 개의 인수가 입력 되어도 단일 값만을 반환한다.
① 가 ② 가, 나 ③ 가, 나, 다 ④ 가, 나, 다, 라
정답 : ②
해설 :
다) 1:M 조인이라 하더라도 M쪽에서 출력된 행이 하나씩 단일행 함수의 입력값으로 사용되므로 사용할 수 있다.
라) 다중행 함수도 단일행 함수와 동일하게 단일 값만을 반환한다.
문제 41
Q. 다음 중, 아래와 같은 2건의 데이터 상황에서 SQL의 수행 결과로 가장 적합한 것은? (단, 이해를 돕기 위해 ↓는 줄바꿈을 의미 → 실제 저장값이 아님, CHR(10) : ASCII 값 → 줄바꿈을 의미)
SELECT SUM(CC)
FROM (
SELECT(LENGTH(C1) - LENGTH(REPLACE(C1, CHR(10))) + 1) CC
FROM TAB 1
)
① 2 ② 3 ③ 5 ④ 6
정답 : ③
해설 : 라인수를 구하기 위해서 함수를 이용해서 작성한 SQL이다. - LENGTH : 문자열의 길이 반환하는 함수 - CHR : 주어진 ASCII 코드에 대한 문자를 반환하는 함수 (CHR(10) : 줄바꿈) - REPLACE : 문자열을 치환하는 함수 (REPLACE(C1, CHR(10)) : 줄바꿈 제거)
① 2015.01.10 11:01:00 ② 2015.01.10 10:05:00 ③ 2015.01.10 10:10:00 ④ 2015.01.10. 10:30:00
정답 : ③
해설 : 오라클에서 날짜의 연산은 숫자의 연산과 같다. 특정 날짜에 1을 더하면 하루를 더한 결과와 같으므로 1/24/60 = 1분을 의미한다. 1/24(60/10) = 10분과 같으므로 2015년 1월 10일 10시에 10분을 더한 결과와 같다.
문제 43
Q. 아래는 SEARCHED_CASE_EXPRESSION SQL 문장이다. 이때 사용된 SEARCHED_CASE_EXPRESSION은 SIMPLE_CASE_EXPRESSION을 이용해 똑같은 기능을 표현할 수 있다. 아래 SQL 문장의 ( ㄱ ) 안에 들어갈 표현을 작성하시오. (스칼라 서브쿼리는 제외함.)
[SEARCHED_CASE_EXPRESSION 문장 사례]
SELECT LOC,
CASE WHEN LOC = 'NEW YORK' THEN 'EAST'
ELSE 'ETC'
END as AREA
FROM DEPT;
[SIMPLE_CASE_EXPRESSION 문장 사례]
SELECT LOC,
CASE ( ㄱ )
ELSE 'ETC'
END as AREA
FROM DEPT;
정답 : LOC WHEN 'NEW YORK' THEN 'EAST'
해설 : SEARCHED_CASE_EXPRESSION을 SIMPLE_CASE_EXPRESSION으로 변환하는 문제이다.
문제 44
Q. 팀별 포지션별 FW, MF, DF, GK 포지션의 인원수와 팀별 전체 인원수를 구하는 SQL을 작성할 때 결과가 다른 것은? (보기 1은 SQL Server 환경이고, 보기 2, 3, 4는 ORACLE 환경이다.)
①
SELECT TEAM_ID,
ISNULL(SUM(CASE WHEN POSITION = 'FW' THEN 1 END), 0) FW,
ISNULL(SUM(CASE WHEN POSITION = 'MF' THEN 1 END), 0) MF,
ISNULL(SUM(CASE WHEN POSITION = 'DF' THEN 1 END), 0) DF,
ISNULL(SUM(CASE WHEN POSITION = 'GK' THEN 1 END), 0) GK,
COUNT(*) SUM
FROM PLAYER
GROUP BY TEAM_ID;
②
SELECT TEAM_ID,
NVL(SUM(CASE POSITION WHEN = 'FW' THEN 1 END), 0) FW,
NVL(SUM(CASE POSITION WHEN = 'MF' THEN 1 END), 0) MF,
NVL(SUM(CASE POSITION WHEN = 'DF' THEN 1 END), 0) DF,
NVL(SUM(CASE POSITION WHEN = 'GK' THEN 1 END), 0) GK,
COUNT(*) SUM
FROM PLAYER
GROUP BY TEAM_ID;
③
SELECT TEAM_ID,
NVL(SUM(CASE WHEN POSITION = 'FW' THEN 1 END), 0) FW,
NVL(SUM(CASE WHEN POSITION = 'MF' THEN 1 END), 0) MF,
NVL(SUM(CASE WHEN POSITION = 'DF' THEN 1 END), 0) DF,
NVL(SUM(CASE WHEN POSITION = 'GK' THEN 1 END), 0) GK,
COUNT(*) SUM
FROM PLAYER
GROUP BY TEAM_ID;
④
SELECT TEAM_ID,
NVL(SUM(CASE POSITION WHEN = 'FW' THEN 1 ELSE 1 END), 0) FW,
NVL(SUM(CASE POSITION WHEN = 'MF' THEN 1 ELSE 1 END), 0) MF,
NVL(SUM(CASE POSITION WHEN = 'DF' THEN 1 ELSE 1 END), 0) DF,
NVL(SUM(CASE POSITION WHEN = 'GK' THEN 1 ELSE 1 END), 0) GK,
COUNT(*) SUM
FROM PLAYER
GROUP BY TEAM_ID;
정답 : ④
해설 : 지문4는 CASE 문장에서 데이터가 없는 경우를 0으로 표시해야(ELSE 0), 다른 3개의 지문과 같은 결과가 나온다.
문제 45
Q. 다음 중 아래 TAB1을 보고 각 SQL 실행 결과를 가장 올바르게 설명한 것을 고르시오.
① SELECT COL2 FROM TAB1 WHERE COL1 = 'b'; →실행 결과가 없다. (공집합) ② SELECT ISNULL(COL2, 'X') FROM TAB1 WHERE COL1 = 'a'; → 실행 결과로 ’X'를 반환한다. ③ SELECT COUNT(COL1) FROM TAB1 WHERE COL2 = NULL; →실행 결과는 1이다. ④ SELECT COUNT(COL2) FROM TAB1 WHERE COL1 IN ('b', 'c'); → 실행 결과는 1이다.
정답 : ②
해설 : ISNULL 함수는 결과값이 NULL일 경우 지정된 값을 반환한다. 칼럼의 NULL 값을 확인할 때는 ISNULL을 사용해야 한다.
문제 46
Q. 사원 테이블에서 MGR의 값이 7698와 같으면 NULL을 표시하고, 같지 않으면 MGR을 표시하려고 한다. 아래 SQL 문장의 ( ㄱ ) 안에 들어갈 함수명을 작성하시오.
SELECT ENAME, EMPNO, MGR ( ㄱ )(MGR, 7698) as NM
FROM EMP;
정답 : NULLIF
해설 : NULLIF(EXPR1, EPXR2) 함수는 EXPR1이 EXPR2와 같으면 NULL을, 같지 않으면 EXPR1을 리턴한다. 특정 값을 NULL로 대체하는 경우에 유용하게 사용할 수 있다.
문제 47
Q. 다음 중 아래 데이터를 가지고 있는 EMP_Q 테이블에서 세 개의 SQL 결과로 가장 적절한 것은?
SELECT SAL/COMM FROM EMP_Q WHERE ENAME = 'KING';
SELECT SAL/COMM FROM EMP_Q WHERE ENAME = 'FORD';
SELECT SAL/COMM FROM EMP_Q WHERE ENAME = 'SCOTT';
※ 단, SCOTT의 COMM은 NULL 값임.
① 0, NULL, NULL ② 0, 에러 발생, 에러 발생 ③ 에러 발생, 에러 발생, NULL ④ 0, 에러 발생, NULL
정답 : ④
해설 : NULL이 포함된 연산의 결과는 NULL이다. 분모가 0이 들어가는 경우 연산 자체가 에러를 발생시킨다. NULL + 2, 2 + NULL, NULL - 2, 2 - NULL, NULL * 2, 2 * NULL, NULL / 2, 2 / NULL 의 결과는 모두 NULL이다.
문제 48
Q. 다음 중 아래와 같은 데이터 상황에서 SQL의 수행 결과로 가장 적절한 것은?
SELECT SUM(COALESCE(C1, C2, C3))
FROM TAB1;
① 0 ② 1 ③ 6 ④ 14
정답 : ③
해설 : COALESCE 함수는 첫번째 NULL이 아닌 값을 반환한다. COALESCE(C1, C2, C3)는 각 행에서 첫번째로 NULL이 아닌 값인 1, 2, 3을 반환한다. 따라서 결과의 합은 6이다.
문제 49
Q. 아래의 각 함수에 대한 설명 중, ( ㄱ ), ( ㄴ ), ( ㄷ )에 들어갈 함수를 차례대로 작성하시오.
( ㄱ )(표현식1, 표현식2) : 표현식1의 결과값이 NULL이면 표현식2의 값을 출력한다. ( ㄴ )(표현식1, 표현식2) : 표현식1이 표현식2와 같으면 NULL을, 같지 않으면 표현식1을 리턴한다. ( ㄷ )(표현식1, 표현식2) : 임의의 개수 표현식에서 NULL이 아닌 최초의 표현식을 나타낸다.
정답 : (ㄱ) : NVL, (ㄴ) : NULLIF, (ㄷ) : COALESCE
해설 : ISNULL, NVL 함수는 표현식1의 결과값이 NULL이면 표현식2의 값을 출력하며, NULLIF 함수는 표현식1이 표현식2와 같으면 NULL을, 같지 않으면 표현식1을 리턴한다. COALESCE 함수는 임의의 개수 표현식에서 NULL이 아닌 최초의 표현식을 나타낸다.
문제 50
Q. 다음 중 아래 각각 3개의 SQL 수행 결과로 가장 적절한 것은?
SELECT AVG(COL3) FROM TAB_A;
SELECT AVG(COL3) FROM TAB_A WHERE COL1 > 0;
SELECT AVG(COL3) FROM TAB_A WHERE COL1 IS NOT NULL;
① 20, 20, 20 ② 20, 10, 10 ③ 10, 20, 20 ④ 10, 10, 10
Q. 어느 기업의 직원 테이블(EMP)이 직급(GRADE) 별로 사원 500명, 대리 100명, 과장 30명, 차장 10명, 부장 5명, 직급이 정해지지 않은(NULL) 사람 25명으로 구성되어 있을 때, 다음 중 SQL문을 SQL1)부터 SQL3)까지 순차적으로 실행한 결과 건수를 순서대로 나열한 것으로 가장 적절한 것은?
SQL1) SELECT COUNT(GRADE) FROM EMP;
SQL2) SELECT GRADE FROM EMP WHERE GRADE IN ('차장', '부장', '널');
SQL3) SELECT GRADE, COUNT(*) FROM EMP GROUP BY GRADE;
① 670, 15, 6 ② 645, 40, 5 ③ 645, 15, 6 ④ 670, 40, 6
정답 : ③
해설 : SQL1은 전체 인원 수를 출력시키고(645), SQL2는 직급이 '차장' 또는 '부장' 또는 '널'인 경우를 출력시키고(15), SQL3는 직급의 수를 출력시킨다.(6)
문제 52
Q. 아래는 어느 회사의 광고에 대한 데이터 모델이다. 다음 중 광고매체ID별 최초로 게시한 광고명과 광고시작일자를 출력하기 위하여 아래 ( ㄱ )에 들어갈 SQL로 옳은 것은?
[SQL]
SELECT C.광고매체명, B.광고명, A.광고시작일자
FROM 광고게시 A, 광고 B, 광고매체 C,
( ㄱ ) D
WHERE A.광고시작일자 = D.광고시작일자
AND A.광고매체ID = D.광고매체ID
AND A.광고ID = B.광고ID
AND A.광고매체ID = C.광고매체ID
ORDER BY C.광고매체명;
①
SELECT D.광고매체ID, MIN(D.광고시작일자) AS 광고시작일자
FROM 광고게시 D
WHERE D.광고매체ID = C.광고매체ID
GROUP BY D.광고매체ID;
②
SELECT 광고매체ID, MIN(광고시작일자) AS 광고시작일자
FROM 광고게시
GROUP BY 광고매체ID;
③
SELECT MIN(광고매체ID) AS 광고매체ID, MIN(광고시작일자) AS 광고시작일자
FROM 광고게시
GROUP BY 광고ID;
④
SELECT MIN(광고매체ID) AS 광고매체ID, MIN(광고시작일자) AS 광고시작일자
FROM 광고게시;
정답 : ②
해설 : 광고게시 테이블에서 광고매체ID별로 광고시작일자가 가장 빠른 데이터를 추출하는 SQL을 작성해야 한다.
문제 53
Q. 다음 중 오류가 발생하는 SQL 문장인 것은?
①
SELECT 회원ID, SUM(주문금액) AS 합계
FROM 주문
GROUP BY 회원ID
HAVING COUNT(*) > 1;
②
SELECT SUM(주문금액) AS 합계
FROM 주문
HAVING AVG(주문금액) > 100;
③
SELECT 메뉴ID, 사용유형코드, COUNT(*) AS CNT
FROM 시스템사용이력
WHERE 사용일시 BETWEEN SYSDATE - 1 AND SYSDATE
GROUP BY 메뉴ID, 사용유형코드
HAVING 메뉴ID = 3 AND 사용유형코드 = 100;
④
SELECT 메뉴ID, 사용유형코드, AVG(COUNT(*)) AS AVGCNT
FROM 시스템사용이력
GROUP BY 메뉴ID, 사용유형코드;
정답 : ④
해설 : 중첩된 그룹 함수의 경우 최종 결과값은 1건이 될 수 밖에 없기 때문에 GROUP BY 절에 기술된 메뉴ID와 사용유형코드는 SELECT 절에 기술될 수 없다.
문제 54
Q. 다음 중 아래와 같은 테이블 A에 대해서 SQL을 수행하였을 때의 결과로 가장 적절한 것은?
CREATE TABLE A
(
가 VARCHAR(5) PRIMIARY KEY,
나 VARCHAR(5) NOT NULL,
다 INT NOT NULL
);
[SQL]
SELECT MAX(가) AS 가, 나, SUM(다) AS 다
FROM A
GROUP BY 나
HAVING COUNT(*) > 1
ORDER BY 다 DESC;
①
②
③
④ 위의 SQL은 SELECT 절에 COUNT를 사용하지 않았으므로, HAVING 절에서 오류가 발생한다.
정답 : ②
해설 : SQL 실행 순서에 의해 HAVING 절은 SELECT 절보다 선행 처리 되기에, SELECT 절 COUNT 함수 사용 여부는 관계 없다. 위의 SQL은 나 칼럼으로 GROUP BY를 수행하였을 때 건수가 2건 이상인 데이터를 추출하여 SUM(다) DML 값이 큰 순으로 정렬하는 SQL이므로 CNT가 2이상인 것만 출력된다.
문제 55
Q. 다음 중 아래 SQL의 실행 결과로 가장 적절한 것은?
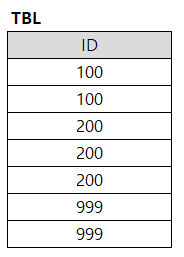
SELECT ID FROM TBL
GROUP BY ID
HAVING COUNT(*) = 2
ORDER BY (CASE WHEN ID = 999 THEN 0 ELSE ID END)
①
②
③
④
정답 : ②
해설 : GROUP BY HAVING 한 결과에 대해 정렬 연산을 하는 것이다. ID 건수가 2개이며, ORDER BY 절 CASE 문에 의해 999는 0으로 치환되고, 그 외는 ID 값으로 정렬된다.
문제 56
Q. 다음 SQL 중 오류가 발생하는 것은?
①
SELECT 지역, SUM(매출금액) AS 매출금액
FROM 지역별매출
GROUP BY 지역
ORDER BY 매출금액 DESC;
②
SELECT 지역, 매출금액
FROM 지역별매출
ORDER BY 년 ASC;
③
SELECT 지역, SUM(매출금액) AS 매출금액
FROM 지역별매출
GROUP BY 지역
ORDER BY 년 DESC;
④
SELECT 지역, SUM(매출금액) AS 매출금액
FROM 지역별매출
GROUP BY 지역
HAVING SUM(매출금액) > 1000
ORDER BY COUNT(*) ASC;
정답 : ③
해설 : GROUP BY를 사용할 경우 GROUP BY 표현식이 아닌 값은 기술될 수 없다. 즉, ORDER BY에는 지역 또는 매출금액만 넣을 수 있다.
문제 57
Q. 다음 중 ORDER BY 절에 대한 설명으로 가장 부적절한 것은?
① SQL 문장으로 조회된 데이터들을 다양한 목적에 맞게 특정 칼럼을 기준으로 정렬하는데 사용한다. ② DBMS 마다 NULL 값에 대한 정렬 순서가 다를 수 있으므로 주의해야 한다. ③ ORDER BY 절에서 칼럼명 대신 Alias 명이나 칼럼 순서를 나타내는 정수도 사용이 가능하나, 이들을 혼용하여 사용할 수 없다. ④ GROUP BY 절을 사용하는 경우 ORDER BY 절에 집계 함수를 사용할 수도 있다.
정답 : ③
해설 : ORDER BY 절에 칼럼명 대신 Alias 명이나 칼럼 순서를 나타내는 정수를 혼용하여 사용할 수 있다.
문제 58
Q. 다음 SQL의 실행 결과로 가장 적절한 것은?
[SQL]
SELECT ID, AMT
FROM TBL
ORDER BY (CASE WHEN ID = 'A' THEN 1 ELSE 2 END), AMT DESC
①
②
③
④
정답 : ②
해설 : CASE 절을 이용해서 원래의 정렬 순서를 변경하였다. 그래서 ID가 'A'인 것이 가장 먼저 표시되도록 하였다.
문제 59
Q. 다음 중 SELECT 문장의 실행 순서를 올바르게 나열한 것은?
① SELECT - FROM - WHERE - GROUP BY - HAVING - ORDER BY ② FROM - SELECT - WHERE - GROUP BY - HAVING - ORDER BY ③ FROM - WHERE - GROUP BY - HAVING - ORDER BY - SELECT ④ FROM - WHERE - GROUP BY - HAVING - SELECT - ORDER BY
정답 : ④
해설 : SELECT 문장의 실행 순서는 프리(FROM)웨어(WHERE) 구(GROUP BY)하(HAVING)세(SELECT)요(ORDER BY)이다.
문제 60
Q. 아래의 팀별성적 테이블에서 승리건수가 높은 순으로 3위까지 출력하되 3위의 승리건수가 동일한 팀이 있다면 함께 출력하기 위한 SQL 문장으로 올바른 것은?
①
SELECT TOP(3) 팀명, 승리건수
FROM 팀별성적
ORDER BY 승리건수 DESC;
②
SELECT TOP(3) 팀명, 숭리건수
FROM 팀별성적;
③
SELECT 팀명, 승리건수
FROM 팀별성적
WHERE ROWNUM <= 3
ORDER BY 승리건수 DESC;
④
SELECT TOP(3) WITH TIES 팀명, 승리건수
FROM 팀별성적
ORDER BY 승리건수 DESC;
정답 : ④
해설 : SQL Server의 TOP N 질의문에서 N에 해당하는 값이 동일한 경우 함께 출력하도록 하는 WITH TIES 옵션을 ORDER BY 절과 함께 사용해야 한다.
문제 61
Q. 다음 중 5개의 테이블로부터 필요한 칼럼을 조회하려고 할 때, 최소 몇 개의 JOIN 조건이 필요한가?
① 2개 ② 3개 ③ 4개 ④ 5개
정답 : ③
해설 : 여러 테이블로부터 원하는 데이터를 조회하기 위해서는 전체 테이블 개수에서 최소 N-1개 만큼의 JOIN 조건이 필요하다.
문제 62
Q. 아래의 영화 데이터베이스 테이블의 일부에서 밑줄 친 속성들은 테이블의 기본키이며, 출연료가 8888 이상인 영화명, 배우명, 출연료를 구하는 SQL로 가장 적절한 것은?
SELECT 출연. 영화명, 영화.배우명. 출연.출연료
FROM 배우, 영화, 출연
WHERE 출연료 >= 8888
AND 출연.영화번호 = 영화.영화번호
AND 출연.배우번호 = 배우.배우번호;
②
SELECT 영화.영화명, 배우.배우명, 출연료
FROM 영화, 배우, 출연
WHERE 출연.출연료 〉8888
AND 출연.영화번호 = 영화.영화번호
AND 영화.영화번호 = 배우.배우번호;
③
SELECT 영화명. 배우명, 출연료
FROM 배우, 영화, 출연
WHERE 출연료〉= 8888
AND 영화번호 = 영화.영화번호
AND 배우번호 = 배우.배우번호;
④
SELECT 영화.영화명. 배우.배우명, 출연료
FROM 배우, 영화, 출연
WHERE 출연료 〉= 8888
AND 출연.영화번호 = 영화.영화번호
AND 출연.배우번호 = 배우.배우번호;
정답 : ④
해설 : 영화명과 배우명은 출연 테이블이 아니라 영화와 배우 테이블에서 가지고 와야 하는 속성이므로 출연 테이블의 영화번호와 영화 테이블의 영화번호 및 출연 테이블의 배우번호와 배우 테이블의 배우번호를 조인하는 SQL문을 작성해야 한다.
문제 63
Q. 다음 중 아래에서 Join에 대한 설명으로 가장 적절한 것은?
가) 일반적으로 Join은 PK와 FK 값의 연관성에 의해 성립된다. 나) DBMS 옵티마이저는 From 절에 나열된 테이블들올 임의로 3개 정도씩 묶어서 Join을 처리한다. 다) EQUI Join은 Join에 관여하는 테이블 간의 걸럼 값들이 정확하게 일치하는 경우에 사용되는 방법이다. 라) EQUI Join은 '=' 연산자에 의해서만 수행되며, 그 이외의 비교 연산자를 사용하는 경우에는 모두 Non EQUI Join이다. 마) 대부분 Non EQUI Join을 수행할 수 있지만. 때로는 설계상의 이유로 수행이 불가능한 경우도 있다.
① 가, 다, 라 ② 가, 나, 다 ③ 가, 나, 다, 라 ④ 가, 다, 라, 마
정답 : ④
해설 : DBMS 옵티마이저는 From 절에 나열된 테이블이 아무리 많아도 항상 2개의 테이블씩 짝을 지어 Join을 수행한다.
문제 64
Q. 다음 SQL의 실행 결과로 맞는 것은?
[SQL]
SELECT COUNT(*) CNT
FROM EMP_TBL A, RULE_TBL R
WHERE A.ENAME LIKE B.RULE;